DWS' AWS Digest Vol.3
yassan
デロイト トーマツ ウェブサービス株式会社(DWS)公式ブログ
[株式会社MMMが2017年度下半期に注力している技術領域(サーバーレス、IoT/AI、クラウドセキュリティ)](https://blog.mmmcorp.co.jp/blog/2017/10/10/Second_half_of_FY2017_MMM/#2.AWS IoT・Amazon AIを初めとした先進技術)という記事で紹介したが、AWS IoT + Amazon Rekognition/Polly + Raspberry Piを使って、映像監視および、異常検知を音声で通知(不審者を威嚇)するシステムをつくってみた。ここでは、その際の設計や情報をまとめてみる。
全体的なサービス設計は以下のようになる。
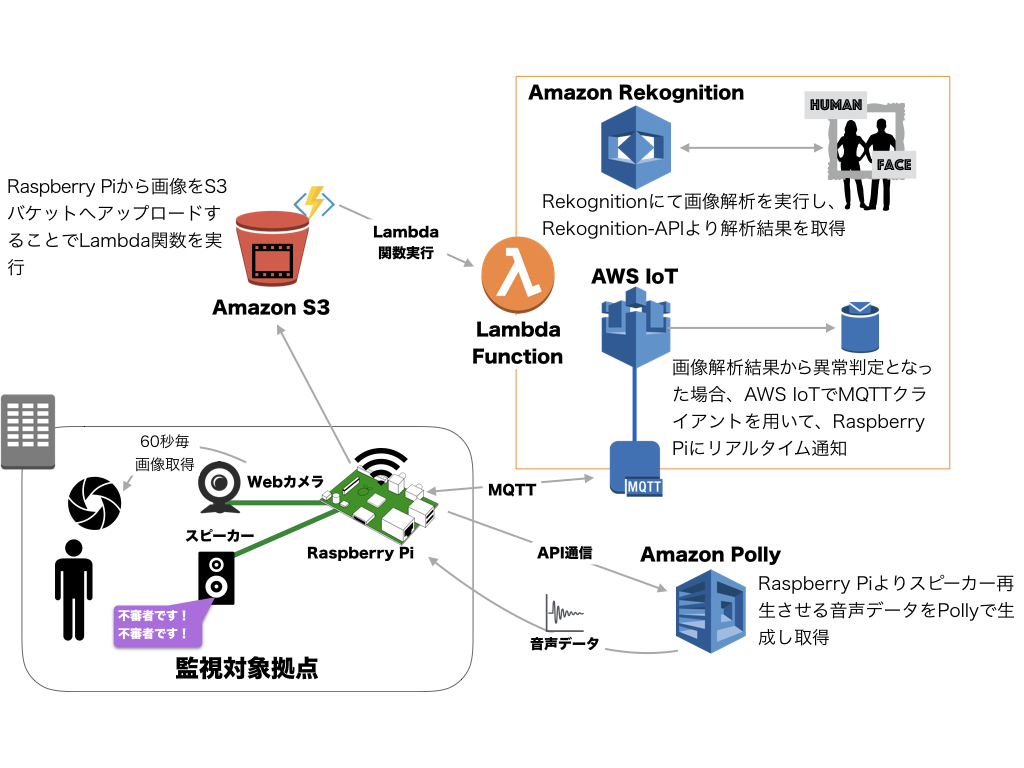
簡単なフローを以下にテキストで記す。
以下で、こちらの設計詳細を紹介してゆく。
Apexを用いてGolangで開発した。
glideenv.jsonを作成し、デプロイ時にapex deploy --env-file env.jsonのように実行する。Nodeで開発した。
npmを使用した。ここからは実際の実装手順を簡単に紹介していこうと思う。
まず、Raspberry Pi側で画像を60秒毎にキャプチャ&アップロードする実装を行う。適当なwebcameraを使ったので、[fswebcam](https://www.Raspberry Pi.org/documentation/usage/webcams/)のNodeラッパーcamelotを使用した。
var path = require('path');
var fs = require('fs')
var Camelot = require('camelot');
var moment = require('moment');
var AWS = require('aws-sdk');
var FREQUENCY = 60;
var s3 = new AWS.S3({
accessKeyId: process.env.AWS_ACCESS_KEY_ID,
secretAccessKey: process.env.AWS_SECRET_ACCESS_KEY,
region: 'us-east-1',
});
var getPath = function(fileName) {
return path.join(__dirname, './' + fileName);
}
var camelot = new Camelot({
device : '/dev/video0',
});
camelot.on('frame', function (image) {
console.log('camelot: success');
var params = {
Body: image,
Bucket: 'BUCKET',
Key: moment().format('YYYY-MM-DD-HH-mm-ss') + '.jpg'
};
s3.putObject(params, function(err, data) {
if (err) {
console.log('s3.putObject: error', err);
}
console.log('s3.putObject: success', data);
});
});
camelot.on('error', function (err) {
console.log('camelot: error', err);
});
camelot.grab({
title: 'TITLE',
frequency: FREQUENCY,
});次にRekognitionによる画像解析を行う。今回はDetectLabels APIで物体検出を行い、特定のラベルがヒットした場合に人だと認識するようにしてみた。
現状だと、"Human", "Person", "People", "Face", "Head", "Selfie"などに設定しているが、知見をためれば、ラベルを追加/削除したり、それぞれのラベルに対する重みを調整したりしてより精度を上げることができると思う。このように、自前で実装すると工数が膨らむAI実装を素早く行うことができる。
package main
import (
"log"
"encoding/json"
"github.com/apex/go-apex"
"github.com/aws/aws-sdk-go/aws/session"
"github.com/aws/aws-sdk-go/service/rekognition"
"github.com/aws/aws-sdk-go/aws"
"rekognition-alert/functions/detectLabels/alerts"
)
func isHuman(name string) bool {
values := []string{"Human", "Person", "People", "Face", "Head", "Selfie"}
for _, v := range values {
if name == v {
return true
}
}
return false
}
func hasConfidence(confidence int) bool {
min := 70
return confidence > min
}
func shouldAlert(labels []*rekognition.Label) bool {
for _, l := range labels {
if isHuman(*l.Name) && hasConfidence(int(*l.Confidence)) {
return true
}
}
return false
}
func main() {
apex.HandleFunc(func(event json.RawMessage, ctx *apex.Context) (interface{}, error) {
type S3Records struct {
S3 struct {
Bucket struct {
Name string
}
Object struct {
Key string
}
}
}
type LambdaEvent struct {
EventType string
Records []S3Records
}
source := (*json.RawMessage)(&event)
var e LambdaEvent
err := json.Unmarshal(*source, &e)
if err != nil {
log.Println("json.Unmarshal: error", err)
}
bucketName := e.Records[0].S3.Bucket.Name
objectKey := e.Records[0].S3.Object.Key
sess, err := session.NewSession(&aws.Config{
Region: aws.String("us-east-1"),
})
if err != nil {
log.Println("session.NewSession()", err)
}
reko := rekognition.New(sess)
input := &rekognition.DetectLabelsInput{
Image: &rekognition.Image{
S3Object: &rekognition.S3Object{
Bucket: aws.String(bucketName),
Name: aws.String(objectKey),
},
},
}
result, err := reko.DetectLabels(input)
if err != nil {
log.Println("reko.DetectLabels(input): error", err)
return nil, err
}
log.Println("reko.DetectLabels(input): result", result)
if shouldAlert(result.Labels) {
// 人が映っていればRaspberry Pi側に通知を行う処理
}
return result, nil
})
}次に、Lambda関数からクライアントであるRaspberry Pi側へ通知を行う。ここで初めて気付いたのだが、AWS Go SDKを使用してのIoT pubsubがまだできなかったようで、NodeでつくったLambda関数をGoから呼び出している。(SDKではなくMQTTクライアントを実装すればGoでも実現可能だが、AWS IoTの恩恵をうけるためにNodeで実装した)。
ここは特定のtopicに対してAPIを投げるだけだったので、特別なことはしていない。
Lambdaでの実装が終わったので、Raspberry Pi側でそれを購読する(AWS IoTとRaspberry Piの設定は省略)。
var fs = require('fs');
var path = require('path');
var iot = require('aws-iot-device-sdk');
var AWS = require('aws-sdk');
var getPath = function(fileName) {
return path.join(__dirname, './' + fileName);
}
var device = iot.device({
keyPath: getPath('certificate/private.pem.key'),
certPath: getPath('certificate/certificate.pem.crt'),
caPath: getPath('certificate/root-ca.crt'),
clientId: 'Raspberry Pi',
port: 8883,
host: process.env.IOT_DATA_ENDPOINT,
});
device.on('connect', function() {
console.log('connect');
device.subscribe('/rekognition/alert'); // 異常の購読開始
require('./camera.js'); // カメラでの映像監視も開始する
});
device.on('message', function(topic, payload) {
// Amazon Pollyで音声読み上げをする処理
});
process.stdin.resume();
process.on('SIGINT', function() {
console.log('SIGINT');
process.exit();
});上記のAmazon Pollyで音声読み上げをする処理は以下のような感じである。Pollyで音声データを返してくれるので、それを再生する。再生はラズパイでうまく動きそうなplay-soundを使用した。
var player = require('play-sound')(opts = {})
var polly = new AWS.Polly({
accessKeyId: process.env.AWS_ACCESS_KEY_ID,
secretAccessKey: process.env.AWS_SECRET_ACCESS_KEY,
region: 'us-east-1',
});
var getPath = function(fileName) {
return path.join(__dirname, './' + fileName);
}
device.on('message', function(topic, payload) {
var spokenText = 'カメラに不審者を検知しました。' // payloadによってテキストを切り替えることもできる
var params = {
OutputFormat: 'mp3',
Text: spokenText,
VoiceId: 'Mizuki',
};
polly.synthesizeSpeech(params, function(err, data) {
if (err) {
console.log(err);
return;
}
console.log('data', data);
var fileName = 'temp.mp3';
fs.writeFileSync(getPath(fileName), data.AudioStream);
player.play(getPath(fileName), function(error) {
if (error) {
console.log('player.play: error', error);
}
console.log('player.play: success');
});
});
});以上で一連の実装は完了し、デバイスは以下のようになる。

npm startで監視を開始、異常を検知した場合、スピーカーから音声を発し、不審者を威嚇する仕様になっている。
実際に一連の流れを実装してみて、改善できそうな点をあげてみた。
Amazon Rekognitionには、コレクションという仕組みがあって、ひとりの人物(コレクション)に対して複数の顔を紐付ける(顔認識する)ことで、1:1の単純な顔比較ではなく、より精度が高い1:多の比較を行うことができる。
これを踏まえて、例えば、カメラに写り込んだ顔を自動的にすべてコレクションに追加しておき、管理画面などで、知人/家族/友人などのラベル付けを行えば、不審者かそうでないかをカメラに学習させることができる。もしくは、「週にX回以上映り込んだ人は知人として認識する」などのプログラムを組んでもいいかもしれない。
このように、APIを組み合わせて、本来時間がかかる部分を省きつつ、より高度なAI実装をすることも可能である。
クライアントからAWS IoTのpublishを実行、Lambda関数をトリガーするなどして、よりクライアント側のコードを減らすことは可能かもしれない。AI実装がAPIで簡単に実装できるので、これらを組み合わせて、より面白いことに取り組んでいけそうだと思った。今後も、他の機械学習系のサービス、フレームワークをウォッチしつつ、実際のビジネスに活用してゆきたい。





