「AWS App2Container」リリースで既存アプリのコンテナ化が容易に - クラウド業界ニュースまとめvol.10 by MMM
mmmuser
デロイト トーマツ ウェブサービス株式会社(DWS)公式ブログ
どうも、対話型の生成系AIでできることがどんどん増えており、毎日ワクワクしているChampです🙌🏼
ついに先日、Amazon BedrockがGAされましたね!
個人的な感想ですが、Amazon Bedrockは公開されたばかりのサービスにも関わらず「AWS での生成系 AI 」ページにツールの先頭に紹介されており、AWSにおける生成系AIの中核を担っていく存在なるのでは?と感じております。
とはいえ、 AWS公式ページの説明を読んだだけでは、どんなサービスなのかイメージしづらいと思います🤔
そこで、Amazon BedrockでClaudeモデルを使用したテキスト生成をワークショップドキュメントをベースに検証する方法を解説します!
Amazon Bedrockは、生成系AIアプリケーションを簡単に構築およびスケーリングするための完全マネージド型サービスです。
基盤モデル(FM)と呼ばれる機械学習モデルが複数提供されており、これらのモデルをAPIを通じて独自のアプリケーションに組み込むことができます。Amazon自体やAI21 Labs、Anthropic、Cohere、Stability AIなど、複数の提供元から選択可能なFMがあります。また、サーバーレスエクスペリエンスと高度なカスタマイズ機能を活用して、インフラストラクチャの手間をかけずにアプリケーションを高度にスケーリングすることができます。
AWSの公式ページでは以下のユースケースが紹介されております。
今回はこちらのリポジトリのコードをベースに検証を行なっていきます。
上記で紹介した様々なユースケースに合わせたサンプルコードがありますが、今回は「テキスト生成」の検証を行いたいと思います。
こちらのリポジトリのサンプル「01_Generation/00_generate_w_bedrock.ipynb」を実行するために以下の準備が必要です。
本記事では説明を割愛させていただきます。詳細はリポジトリのREADMEを参照してください。
※モデルアクセスへの許可方法についてはこちらの記事にて紹介しております
テキスト生成の検証では、01_Generation/00_generate_w_bedrock.ipynbというサンプルコードを使用します。
このサンプルは、amazon.titan-tg1-largeモデルを使用し、プロンプトに基づいて新しいテキストを生成するというものです。
しかし、amazon.titan-tg1-largeモデルは利用可能なモデル一覧にないためそのままではコードが実行できません。(2023/10/11時点)
以下の画像は、2023/10/11時点でus-east-1で利用可能なモデルの一覧です。
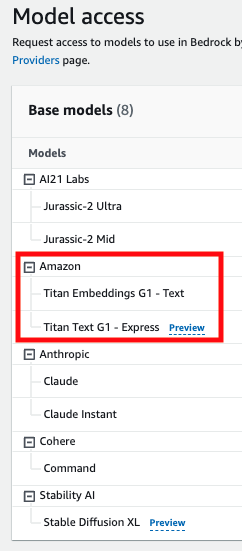
そのため、今回はanthropic.claude-v2 モデルを使用してサンプルコードを実行していきたいと思います。
以降の手順ではサンプルコードから変更した点に重きを置いて説明します。
サンプルコードのまま、問題なく実行できると思います。エラーが出た場合はリージョンやPROFILEが正しく設定できていることを確認してください。
import json, os, sys, boto3
module_path = ".."
sys.path.append(os.path.abspath(module_path))
from utils import bedrock, print_ww
os.environ["AWS_DEFAULT_REGION"] = "us-east-1" # モデルアクセスを許可したリージョンを設定
os.environ["AWS_PROFILE"] = "<YOUR_PROFILE_NAME>"
boto3_bedrock = bedrock.get_bedrock_client(
assumed_role=os.environ.get("BEDROCK_ASSUME_ROLE", None),
region=os.environ.get("AWS_DEFAULT_REGION", None)
)Amazon Bedrockで使われるモデルによっては、APIリクエストのBody内のプロンプト形式が異なることがあります。例えばanthropic.claudeモデルを使用する場合、プロンプトの形式には特定のルールがあります。
Claudeモデルでは、プロンプトは必ずHuman:で始め、その後に具体的な指示を記述し、最後にAssistant:で終える必要があります。これはBedrockの仕様ではなく、Claudeモデル自体の仕様です。詳しくはClaudeのAPIリファレンスをご参照ください。
変更前のプロンプト
prompt_data = """
Command: Write an email from Bob, Customer Service Manager, to the customer "John Doe"
who provided negative feedback on the service provided by our customer support
engineer"""変更後のプロンプト
prompt_data = """
Human: Write an email from Bob, Customer Service Manager, to the customer "John Doe"
who provided negative feedback on the service provided by our customer support
engineer
Assistant:"""ちなみに、プロンプトで依頼している内容は「コマンド カスタマーサービスマネージャーのBobから、カスタマーサポートエンジニアのサービスに対して否定的なフィードバックをした顧客 "John Doe "にメールを送ってください。」です。
一体、どんなメールを書いてくれるのか気になります。。。!
anthropic.claude-v2 モデルを使用するため、サンプルコードではamazon.titan-tg1-largeと指定されていた部分を、anthropic.claude-v2に変更します。
変更前
modelId = 'amazon.titan-tg1-large'変更後
modelId = 'anthropic.claude-v2'モデルごとにbodyに必要なパラメータが違うため、こちらも変更します。
変更前
body = json.dumps({
"inputText": prompt_data,
"textGenerationConfig":{
"maxTokenCount":4096,
"stopSequences":[],
"temperature":0,
"topP":0.9
}
}) 変更後
body = json.dumps({
"prompt": prompt_data,
"max_tokens_to_sample": 4096,
"temperature": 0,
"top_p": 0.9,
"stop_sequences": [
"\\n\\nHuman:"
]
})これらのパラメータは一般から公式ドキュメントもしくはコンソール画面(Amazon Bedrock > Providers > Models)の以下の箇所から確認ができます。
前述のboto3_bedrockクライアントを用いて、Claudeモデルを呼び出します。
こちらもサンプルコードのまま、問題なく実行できると思います。
response = boto3_bedrock.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)もしエラーが発生した場合は、「実行したリージョンで対象のモデルが利用可能になっているか」「bodyが適切に設定されているか」をご確認ください。
Claudeモデルからの出力を表示します。
ここにも注意すべきポイントがあるのですが、 使用するモデルに応じてレスポンス形式も変わります。そのためサンプルコードのままでは動かないので、以下のように変更を加えます。
変更前:amazon.titan-tg1-largeの形式
outputText = response_body.get('results')[0].get('outputText')変更後:anthropic.claude-v2の形式
outputText = response_body.get('completion') 参考までに、私が実行した結果は以下となります。
完了まで約12秒かかりました。
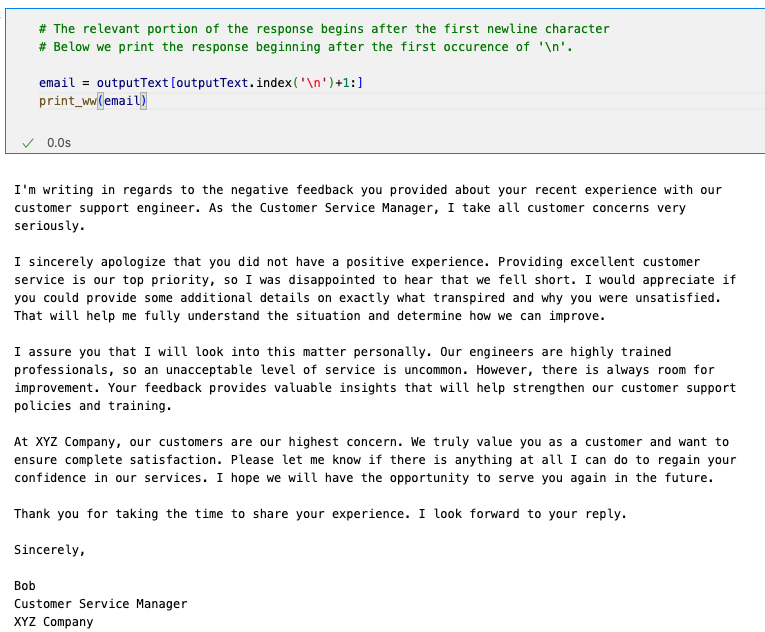
出力結果を機械翻訳したメールは以下になります。
一部気になる点もありますが、結構いい感じですね!
カスタマーサポートエンジニアとの最近の経験についてご提供いただいた否定的なフィードバックについて、ご連絡いたします。
カスタマー・サービス・マネージャーとして、私はすべてのお客様のご懸念を真摯に受け止めております。
お客様にとって良い経験にならなかったことを心よりお詫び申し上げます。
優れたカスタマーサービスを提供することは私たちの最優先事項ですので、このようなご指摘をいただき残念に思います。
何が起こったのか、なぜご満足いただけなかったのか、詳細をお聞かせいただければ幸いです。
そうすることで、状況を十分に理解し、どのように改善できるかを判断することができます。
この件につきましては、私が個人的に調査することをお約束いたします。
私たちのエンジニアは高度な訓練を受けたプロフェッショナルですので、ご満足いただけないレベルのサービスはまずありません。
しかし、常に改善の余地はあります。
お客様からのフィードバックは、カスタマーサポートの方針とトレーニングの強化に役立つ貴重な洞察となります。
XYZ社では、お客様を第一に考えています。
私たちはお客様を本当に大切にし、完全にご満足いただけるようにしたいと考えています。
当社のサービスに対するお客様の信頼を回復するために、私にできることがありましたら、何なりとお申し付けください。
また機会がありましたら、よろしくお願いいたします。
貴重なお時間を割いていただき、ありがとうございました。
ご回答をお待ちしております。
敬具
ボブ
カスタマーサービス・マネージャー
XYZ社ということで、Claudeモデルを使用してサンプルコードを実行するポイントを解説してきました!
Bedrockは一つのAPIを使用し、さまざまなLLMを実行可能なサービスです。万能なLLMはまだないと言われており、ユースケースに応じたLLMを選択することが大切な現状では良いサービスだと感じました!
今回の記事で最低限の実行ができたので、次回は「テキスト要約」や「RAG(検索拡張生成)の手法を使ったChatBotの作成」などを解説していきたいと思います。
それでは、またどこかで!