AWS Jamって何? 〜AWS Ambassador/Japan Top Engineer向け体験会に参加してきました〜
sho
デロイト トーマツ ウェブサービス株式会社(DWS)公式ブログ

最近の週末はゲームばかりやっています。内山です。
2019年6月に Amazon Personalize というサービスが一般提供開始となりました。
今回は、このサービスを活用し、記事推薦システムを構築した話をしたいと思います。
Amazon Personalize
https://aws.amazon.com/jp/personalize/
Amazon Personalize は、機械学習の知識がなくても、レコメンド機能を簡単に開発することができるサービスです。EC サイトである Amazon.com で実際に使われている技術を基にしていて、同サイトでよく見かける以下のようなレコメンド機能を開発することができます。
__これらの機能を開発するために必要なことは、インタラクションデータ(CSVファイル)を用意することだけです。__インタラクションとは、ユーザー が 商品 に対して行った行為(クリック/購入/いいね評価など)のことを指します。
用意したインタラクションデータを Personalize にインポートすれば、学習させることができます。__学習用アルゴリズムの実装や学習用パラメータの調整など、機械学習の知識が必要となってくるような部分に関しては Personalize が面倒をみてくれます。__学習が終わると、レコメンド機能が使えるようになります。
今回は、このサービスを活用して構築した__記事推薦システム__についてご紹介したいと思います。
その前に、Personalize の用語やワークフローを簡単にご紹介します。
Personalize のワークフローは以下のようになります。
Personalize で使用する学習データセットは、以下の三種類あります。
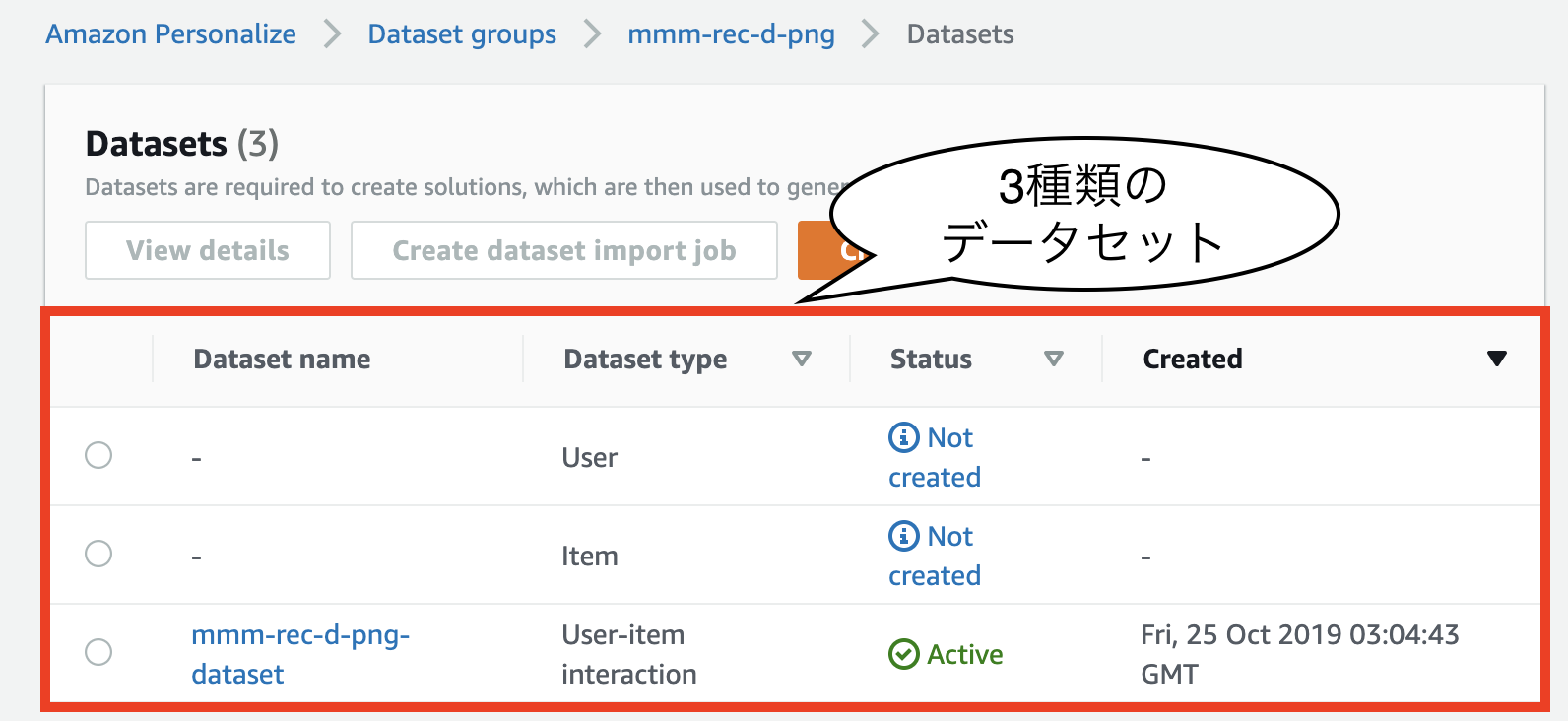
それぞれ1つのCSVファイルとしてインポートします。
Interactions のみが必須で、 Users や Items は次のステップで選択するレシピによっては必須になる場合があります。Interactions は、ユーザー と アイテム の間の過去のインタラクション(クリック/購入/評価など)を含んだCSVデータで、以下の3つのカラムを含みます。
TIMESTAMP USER_IDITEM_IDCSVファイルはS3に配置し、Personalize に読み込ませてインポートします。
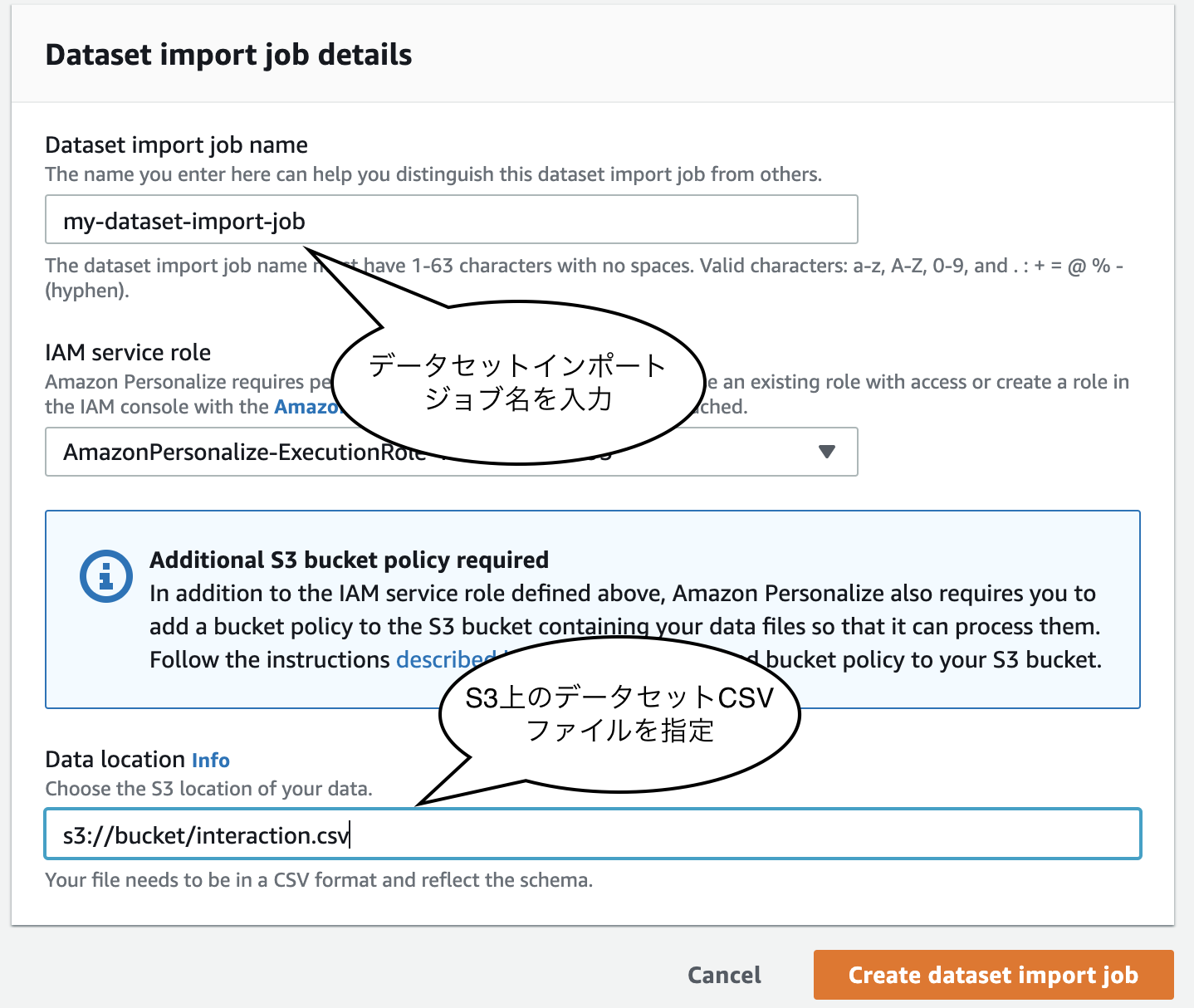
ソリューションバージョンとは Personalize の用語で、学習モデルのことです。
ソリューションバージョンを作成するためには、事前に用意されているレシピを選択します。レシピとは、Personalize の用語で、学習用アルゴリズムのことです。Personalize が自動でレシピを選択する設定もできます。前述したとおり、レシピによっては Users や Items のデータセットが必要となってきます。
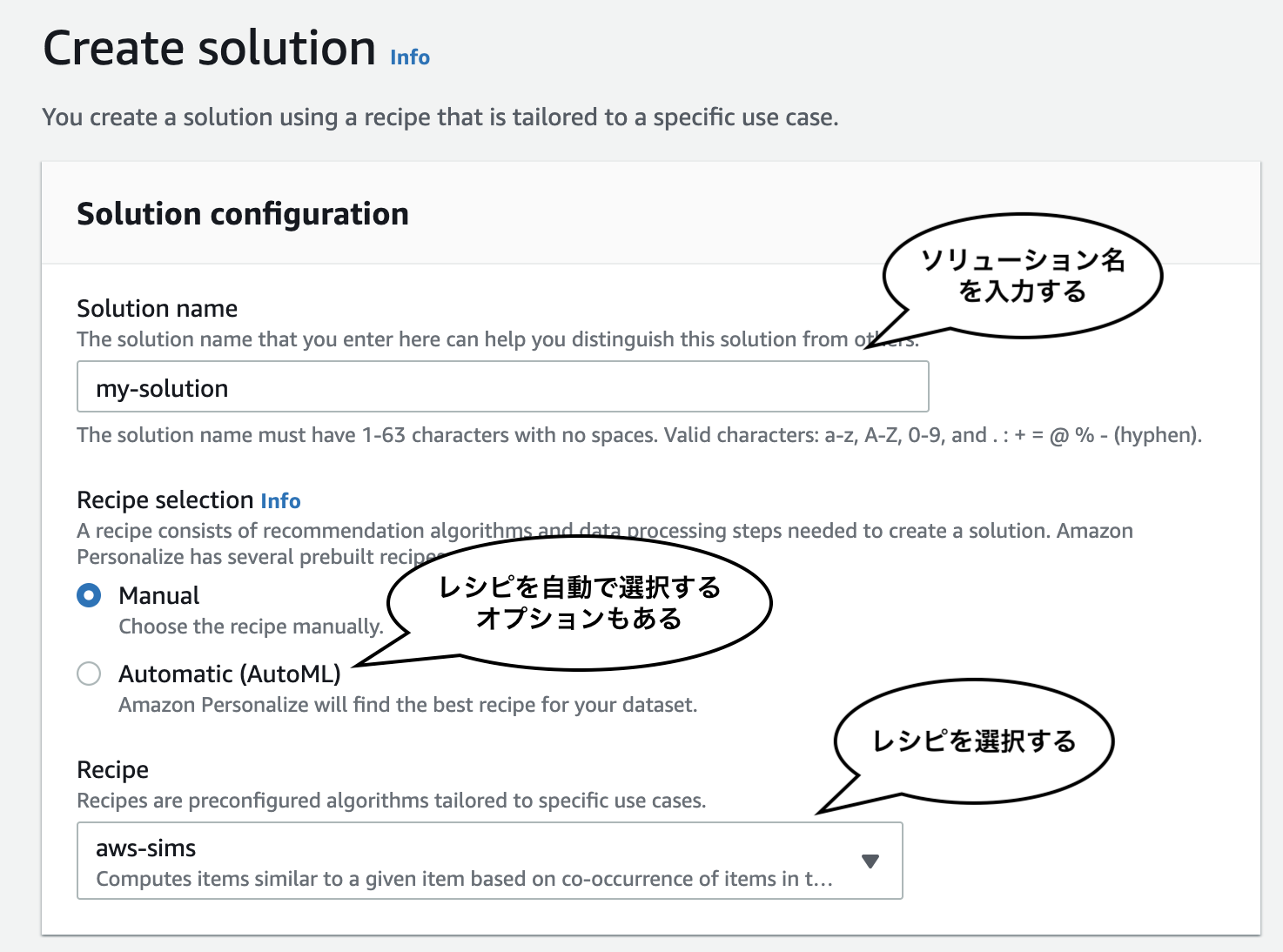
Personalize は、選択されたレシピに従って、インポートされたデータセットを学習し、ソリューションバージョンを作成します。
キャンペーンとは Personalize の用語で、デプロイされたソリューションバージョンのことです。
レコメンドリストを取得する場合は、キャンペーンを通じて取得する流れになります。キャンペーンとしてデプロイされていないソリューションバージョンからは取得できません。
Personalize は、選択されたソリューションバージョンを基に、キャンペーンを作成します。
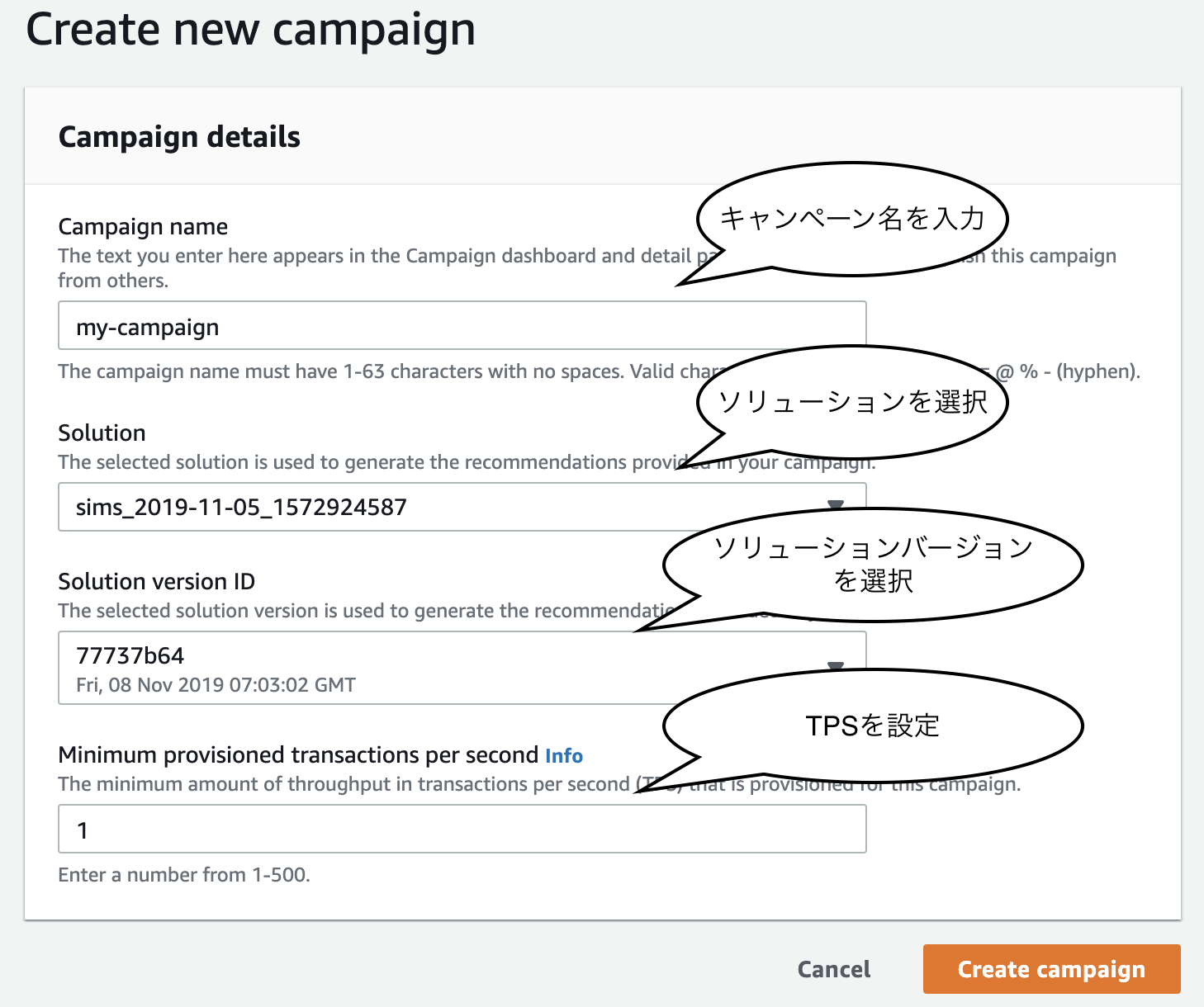
デプロイした後は、使用するソリューションバージョンを変更することもできます。
注意が必要なのが、キャンペーンにかかる費用です。
キャンペーンを動かし続けているだけで、月に最低1万円弱はかかります。
また、キャンペーンに短時間にリクエストを送った場合も、無視できない費用がかかります。__テストで作成した複数のキャンペーンを放置したり、テストでリクエストを短時間で送ったりしないよう__に注意する必要があります。
キャンペーンからレコメンドリストを取得するには、AWS コンソールや SDK を使います。取得する際に渡す引数は、レコメンドの種別によって異なります。
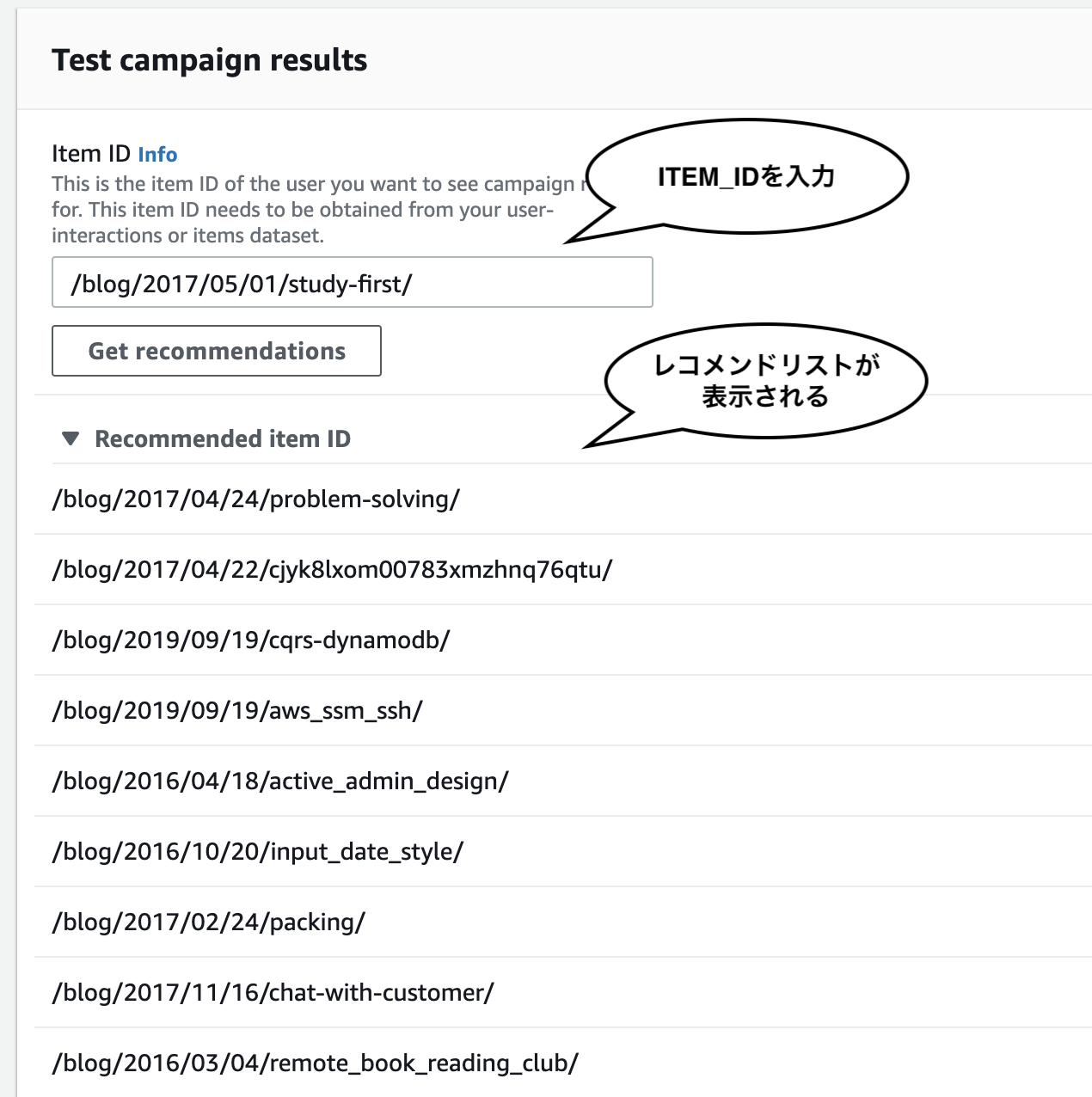
以上で、 Personalize のワークフローを見てきました。
次に、このサービスを活用して開発した記事推薦システムについてご紹介します。
Amazon Personalize を活用して、ブログ記事を推薦するシステムを開発しました。このシステムは、ブログの読者が現在読んでいる記事に関連する記事(「この記事を読んでいる人は、こんな記事も読んでいます」)を表示する機能を提供します。
アーキテクチャは、__Personalize/Lambda/Athena/StepFunctions などを用いたサーバレス構成__となっています。
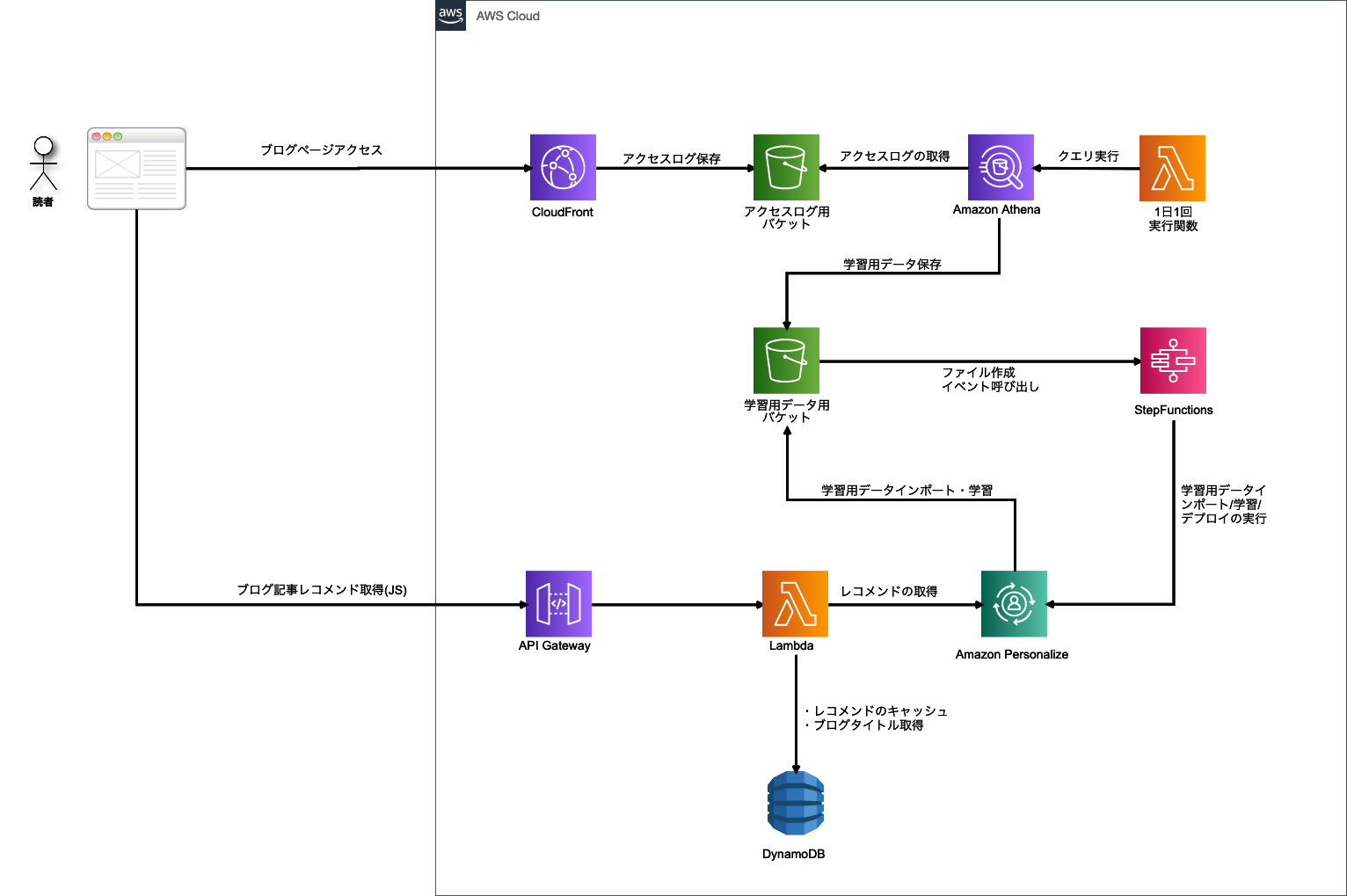
このアーキテクチャにしたのは、以下のような目的があります。
これらを実現するために、以下のような実装を行っています。
各種実装について、解説していきたいと思います。
まずはじめに、学習用データセットの基となるアクセスログを取得できるようにします。MMM ブログは CloudFront 経由で配信されているため、 S3 にアクセスログを出力させるように設定します。設定方法や仕組みについては、以下のページをご参照ください。
アクセスログの設定および使用
https://docs.aws.amazon.com/ja_jp/AmazonCloudFront/latest/DeveloperGuide/AccessLogs.html
Athena は、S3 に保存されているデータを SQL で取得可能にするサーバレスなサービスです。今回は CloudFront のアクセスログから 学習用データセットを抽出するために使用しています。
まず、S3 バケットにある CSV ファイルに対応付けるテーブルを定義します。以下のクエリで、テーブルを作成しています。
CREATE EXTERNAL TABLE IF NOT EXISTS cf_logs (
request_date STRING,
request_time STRING,
x_edge_location STRING,
sc_bytes INT,
client_ip STRING,
cs_method STRING,
cs_host STRING,
cs_uri_stem STRING,
sc_status STRING,
cs_referer STRING,
user_agent STRING,
uri_query STRING,
cookie STRING,
x_edge_result_type STRING,
x_edge_request_id STRING,
x_host_header STRING,
cs_protocol STRING,
cs_bytes INT,
time_taken DECIMAL(8,3),
x_forwarded_for STRING,
ssl_protocol STRING,
ssl_cipher STRING,
x_edge_response_result_type STRING,
cs_protocol_version STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ' ',
'input.regex' = ' '
)
LOCATION 's3://bucket/blog'
TBLPROPERTIES ('has_encrypted_data'='false');SQL 内の LOCATION で、S3 バケットを指定しています。テーブルのカラムは、CSV のフォーマットに合わせて、名前付けを行っています。今回主に使うカラムは、以下のとおりです。
| カラム名 | 概要 | 使用目的 |
|---|---|---|
| request_date | アクセス日時 | TIMESTAMPとして使用 |
| request_time | アクエス時刻 | TIMESTAMPとして使用 |
| client_ip | アクセス元IPアドレス | USER_ID として使用 |
| cs_uri_stem | ブログ記事URI | ITEM_ID として使用 |
以下のように、抽出用クエリでは、これらのカラムを SELECT する形となっています。
SELECT
CAST(to_unixtime(date_parse(request_date || ' ' || request_time, '%Y-%m-%d %H:%i:%s')) AS INTEGER) AS TIMESTAMP,
cs_uri_stem AS ITEM_ID,
client_ip AS USER_ID
FROM
cf_logs
WHERE
regexp_like(cs_uri_stem, '^/blog/[0-9]{4}/[0-9]{2}/[0-9]{2}/[0-9a-zA-Z_-]+/$')
AND request_date BETWEEN '###start_date###' AND '###end_date###'
GROUP BY
request_date, request_time, cs_uri_stem, client_ipクエリ結果は、S3 に CSV ファイルとして保存します。内容の一部は以下のようになっています(xxx.xxx.xxx.xxxの部分は実際はIPアドレス)。
"TIMESTAMP","ITEM_ID","USER_ID"
"1569896114","/blog/2016/09/23/android_smartphone/","xxx.xxx.xxx.xxx"
"1569909332","/blog/2018/11/16/markdown-to-pdf-document/","xxx.xxx.xxx.xxx"
"1569886114","/blog/2015/07/18/aws-solution-architect/","xxx.xxx.xxx.xxx"
"1569861564","/blog/2017/07/14/serverless-dev-flow/","xxx.xxx.xxx.xxx"
"1569847637","/blog/2019/02/09/appsync-lambda-golang/","xxx.xxx.xxx.xxx"
"1569839945","/blog/2018/11/16/markdown-to-pdf-document/","xxx.xxx.xxx.xxx"
"1569880794","/blog/2019/01/27/about-setapp/","xxx.xxx.xxx.xxx"
"1569894938","/blog/2016/02/05/css_arrow/","xxx.xxx.xxx.xxx"
"1569847498","/blog/2016/02/05/css_arrow/","xxx.xxx.xxx.xxx"
"1569821458","/blog/2015/07/18/aws-solution-architect/","xxx.xxx.xxx.xxx"
"1569906304","/blog/2017/08/04/css_shapes/","xxx.xxx.xxx.xxx"
"1569842664","/blog/2015/12/12/aws_lambda/","xxx.xxx.xxx.xxx"
"1569899293","/blog/2018/03/22/sql_order_by/","xxx.xxx.xxx.xxx"
"1569850602","/blog/2019/08/11/communication-stack/","xxx.xxx.xxx.xxx"
"1569909527","/blog/2018/05/19/cloudwatch_custom_metrics/","xxx.xxx.xxx.xxx"
"1569849534","/blog/2015/12/21/redux-test/","xxx.xxx.xxx.xxx"この CSV ファイルがそのまま Personalize の学習用データセットとしてインポートされます。
Step Functions は、複数の Lambda を組み合わせて、バッチ処理を実装できるサービスです。
Personalize ワークフロー(データセットインポート・学習・デプロイ)は Step Functions で実行するように実装しています。
Athena によって作成される CSV ファイルが S3 に保存されたときにイベントが発火するように設定します。S3 のイベント設定から直接 Step Functions を実行することは現在できないため、Cloud Trail 経由で行うように設定します。
Amazon S3 イベント発生時にステートマシンの実行を開始する
https://docs.aws.amazon.com/ja_jp/step-functions/latest/dg/tutorial-cloudwatch-events-s3.html
データインポート処理のために定義した Step Functions のステートマシンは、以下のような形になっています。
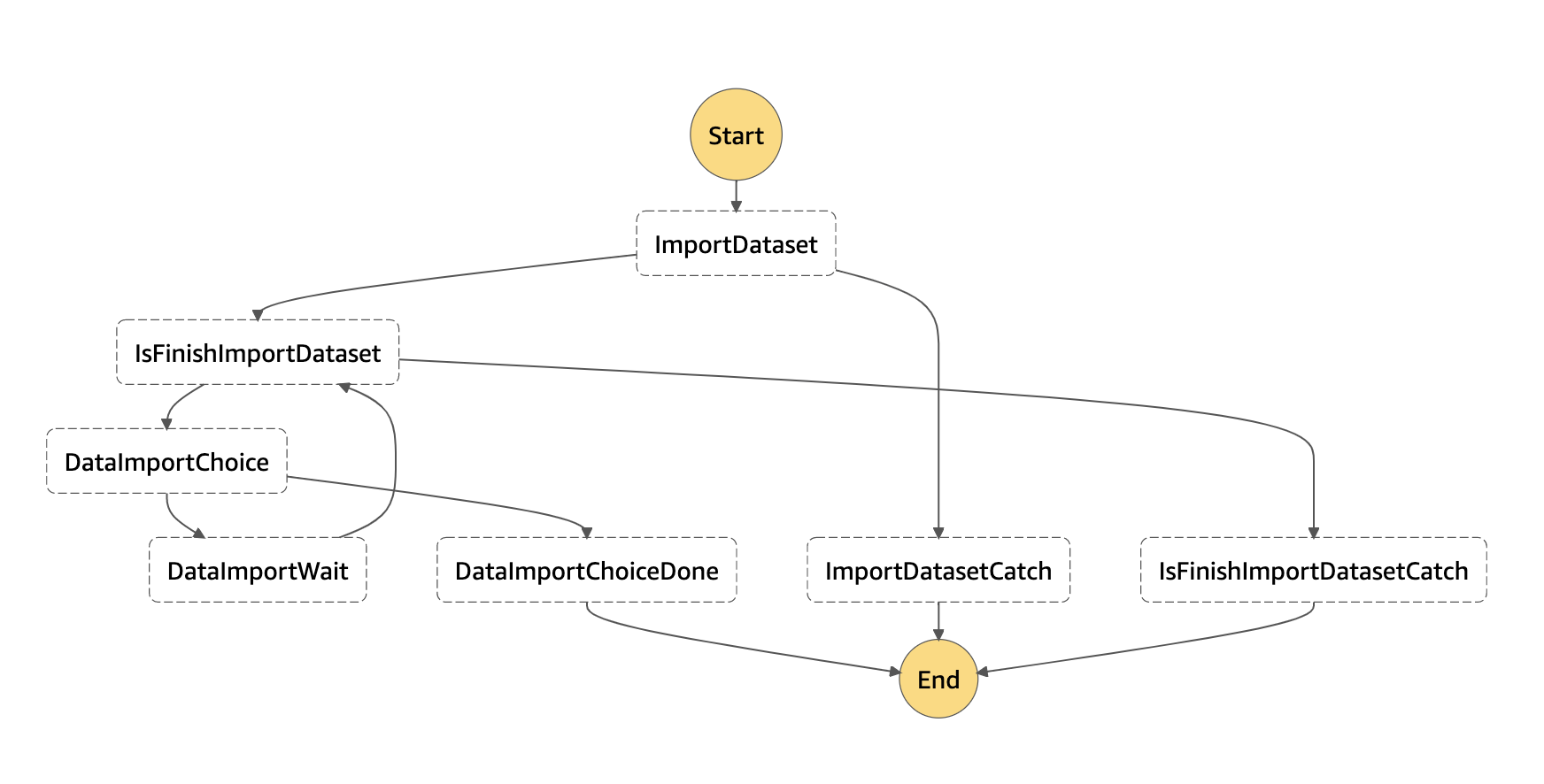
処理の流れは以下のようになっています。
ImportDataset で、データセットインポートジョブを作成する Lambda 関数を実行するIsFinishImportDataset で、データセットインポートジョブのステータスを確認して、終了しているかどうかのフラグを立てる Lambda 関数を実行するDataImportChoice で、フラグを確認し、true であれば DataImportChoiceDone、false であれば、DataImportWait に処理を遷移させるDataImportWait で、1分間処理を停止し、IsFinishImportDataset へ戻る学習やデプロイの処理も同じように実装していて、合計3つのステートマシンを作成しました。さらにこの3つをすべて実行するステートマシンも実装しています。
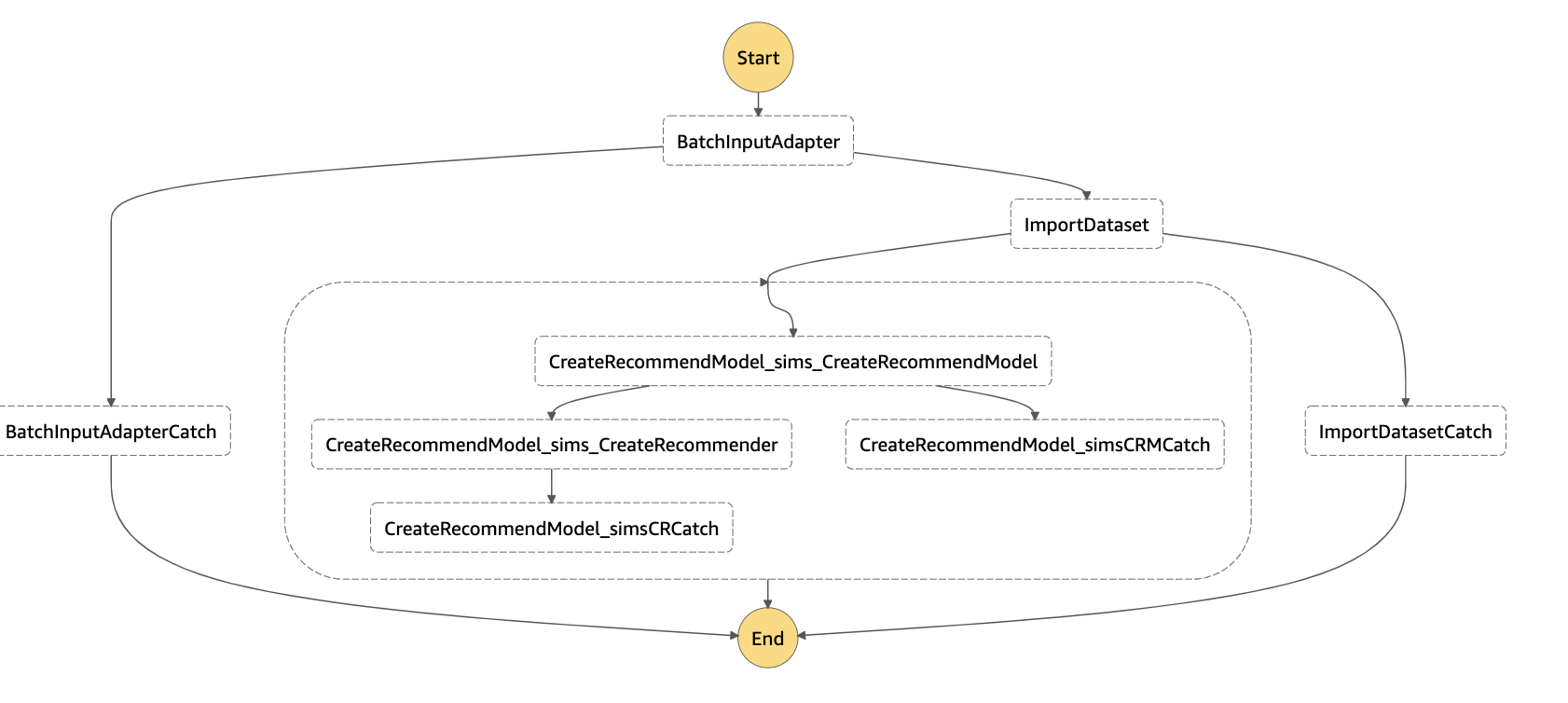
ImportDataset CreateRecommendModel_sims_CreateRecommendModel CreateRecommendModel_sims_CreateRecommender がそれぞれの処理を行うステートマシンです。
このステートマシンが実行されると、Personalize にキャンペーンが作成されます。
ちなみに、以下のように Go 言語で、ステートマシンの処理の流れを記述すると、
// ImportDataset データセットインポート処理
func ImportDataset(b *StateMachineBuilder) *StepFunctionDefinition {
return b.StepFunctionDef(
"DataImport",
&mainlambda.ImportDatasetInput{},
b.ItrStateMachineDef(
b.TaskFuncWithCatcher(mainlambda.ImportDataset, "ImportDatasetCatch"),
b.TaskFuncWithCatcher(mainlambda.IsFinishImportDataset, "IsFinishImportDatasetCatch"),
"DataImportChoice",
*b.StepFunctionWithStates(
"DataImportWait",
nil,
b.Wait("DataImportWait", FinishCheckIntervalSeconds),
),
func(doneState *PassState) {
doneState.OutputPath = "$.job_id"
}))
}が行われる仕組みを実装しています。
この部分については、また別の機会でご紹介します。
API Gateway + Lambda + DynamoDB で、WebAPI を実装します。ブログページ上の JavaScript から Web API 経由で推薦記事を取得できる想定となっています。
DynamoDB は、Personalize で取得したレコメンドリストのキャッシュを保存するために使用します。もし、何かの記事がバズったときに、短時間のうちにレコメンド取得リクエストが Personalize に行かないようにしています。__短時間のうちにリクエストが行くと、莫大な料金がかかってしまう恐れがあるためです__。
Web API を curl コマンドで叩くと以下のような結果が返ってきます。
$ curl https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/d/v1/similar_articles?article_id=/blog/2019/10/28/sc_exam/ | jq
{
"articles": [
{
"url": "/blog/2017/05/01/study-first/",
"title": "新人プログラマの時に知っておきたかった1年目に本当に勉強すべきこと"
},
{
"url": "/blog/2017/04/24/problem-solving/",
"title": "新人プログラマの時に知っておきたかったハマったときのフローチャートと基本思考"
},
{
"url": "/blog/2018/11/16/markdown-to-pdf-document/",
"title": "Markdownを印刷しやすいPDFにする時に私がしていること"
},
{
"url": "/blog/2015/07/18/aws-solution-architect/",
"title": "新卒入社4ヶ月でAWS 認定ソリューションアーキテクトに合格した話"
},
{
"url": "/blog/2018/01/30/adobe-xd_archives-pdf/",
"title": "Adobe XDのプロトタイプをPDFで保存する"
},
{
"url": "/blog/2017/07/14/serverless-dev-flow/",
"title": "Serverless Framework+Node.jsをつかったLambda関数の開発フロー"
},
{
"url": "/blog/2014/10/30/active-resourrce-patch/",
"title": "ActiveResourceでGET送信時に配列で渡す"
},
{
"url": "/blog/2018/11/11/postman/",
"title": "Postmanを使ってProxy経由でAPIにアクセスする方法"
},
{
"url": "/blog/2017/01/20/far-sightedness/",
"title": "PC仕事と遠視について"
}
]
}この Web API は、実際に JavaScript などのコードから実行されることになります。
以上が、実装の解説となります。
今回は、ブログ記事推薦システムを構築しましたが、Personalize は様々なユースケースに対応しているので、別のレコメンデーションシステムを構築することも可能です。
例えば、
といったケースです。今回構築したシステムでは、__一部のコンポーネントを入れ替えるだけで、これらのケースに対応させることが可能となっています__。
また、実装解説には入れませんでしたが、Serverless Framework や Terraform を利用した Infrastructure as Code も行っているので、別の AWS 環境にデプロイしていくことも可能になっています。
今後は、サーバレスを活用した機械学習システムの構築を、さらに容易に行えるようにしていきたいと考えています。
Amazon Personalize を活用した事例として、記事推薦システムの構築についてご紹介しました。
MMM ブログは WordPress に移行予定で、そのタイミングで記事推薦システムが導入されます。近日中に推薦記事が表示されるようになりますので、ご期待ください。
MMM では、Amazon Personalize やサーバレスシステムのご相談をお待ちしております。
https://mmmcorp.co.jp/service/serverlessarchitecture
また、機械学習やサーバレスを活用した開発をしたいエンジニアを募集しています。
https://www.wantedly.com/projects/10749





