React で複雑な表を表現するためのライブラリ
sekky
デロイト トーマツ ウェブサービス株式会社(DWS)公式ブログ
新年度一発目の記事を担当します。伊藤です!
今年度からは機械学習を使った行動ログの解析を行うなど、リサーチエンジニア的な仕事も頑張ります!
MMMブログでは、ブログ検索で2015年を振り返る に書かれているように3ヶ月前にブログ内検索の機能が実装され、気になる記事を簡単に探せるようになりました。毎週2本ずつ投稿されるこのブログではこの記事を含めて160本があり、検索機能なしでは読みたい記事を探すのが難しい規模であるため、これは大変嬉しい機能追加でした。
しかし、一方 検索 は検索する適切なキーワードを自分で考えるという能動的な行動が必要となり、若干ハードルが高いものでもあります。もっと気軽にいろいろな記事を読み漁って欲しいという思いもあり、類似記事をレコメンドするシステムを作ってみました。
なお、レコメンドエンジンの実装はすでに完了していますが、レコメンドの精度を含めて現在社内レビューの段階にあり、本当に機能追加されるかはまだ未定です!笑
文章間の類似度計算に一般的に使われる手法を用いており、特に複雑なことはしていません。ブログ記事内の文章を MeCab を使い形態素解析を行い、その後 TF-IDF で単語の特徴ベクトルを計算します。最後に記事間の類似度を、TF-IDF の特徴ベクトルのコサイン類似度を用いて判断します。
以下でもう少し細かく処理の説明をします。
このブログ記事はマークダウン記法で書かれているため、形態素解析を行う前に余分な記号を取り除く前処理が必要です。
例えば、この記事の先頭部分は以下のように書かれています。
---
title: 'ブログの類似記事レコメンドエンジンを作ってみた'
date: 2016-04-05 17:24:06
tags:
- レコメンド
- 機械学習
- TF-IDF
id: blog-recommendation
author: 伊藤 勝梧
---
新年度一発目の記事を担当します。伊藤です!
今年度からは機械学習を使った行動ログの解析を行うなど、リサーチエンジニア的な仕事も頑張ります!
## 背景
MMMブログでは、[ブログ検索で2015年を振り返る](http://blog.mmmcorp.co.jp/blog/2016/01/13/blog-search/) に書かれているように3ヶ月前にブログ内検索の機能が実装され、気になる記事を簡単に探せるようになりました。--- に囲まれた部分はこの記事のメタ情報が YAML 形式で記述されており、その後にマークダウン記法での文章が続きます。
これに対してクリーニングを行い、以下のようにします。
新年度一発目の記事を担当します。伊藤です!
今年度からは機械学習を使った行動ログの解析を行うなど、リサーチエンジニア的な仕事も頑張ります!
背景
MMMブログでは、 ブログ検索で2015年を振り返る に書かれているように3ヶ月前にブログ内検索の機能が実装され、気になる記事を簡単に探せるようになりました。メタ情報部分や ##, []() などのマークダウン記法を除外し、文章の文字列のみにします。
アルゴリズムの概要でも説明したとおり、MeCab を使用しています。標準の辞書では リモートワーク が リモート と ワーク に分割されてしまったり、 E2Eテスト が E 2 E テスト とバラバラになってしまうので、それらを正しく解析できるようにユーザ辞書を作成しました。と言ってもすべてのIT/ソフトウェア系の単語を救うのは不可能なので、解析した結果を自分の目で確認して、これはマズイな…と思う単語だけをピックアップして登録しました。
文章の類似度を計算するときには名詞だけを用いるのが一般的だと思いますので、今回もそのようにしています。ただ、 品詞が名詞の単語すべてを使用した場合にあまり精度が良くなかったため、品詞細分類が 一般 と 固有名詞 のものだけを抽出するようにしました。
TF-IDF による単語の特徴ベクトル計算には kyow/tfidf_ja のライブラリを使用しています。README を読むと
・IDF辞書
IPADIC辞書に収録されている日本語の形態素(約32万語)を使用し、TF値をYahoo!のインデックス数としてあらかじめ算出。
と書かれています。TF値をYahoo!のインデックス数としてあらかじめ算出。 の部分がよく理解できませんでしたが、一般的な文章における単語の出現頻度を IDF 辞書として持っているのだとなんとなく解釈しました。ブログ内の記事だけを用いて IDF を計算すると、記事自体が少なく学習量が不十分なため kyow/tfidf_ja の IDF 辞書を使うよりも精度が悪くなってしまいました。
ちなみに先程から 精度が悪い という言葉がでてきますが、なにか客観的な指標を用いて判断しているわけではなく、類似度の高い記事の良し悪しを私の主観で判断しているだけです。
記事毎に TF-IDF で算出した単語の特徴ベクトルのコサイン類似度を計算して、記事間の類似度を判断します。コサイン類似度の値が大きければ類似度が高いといえるので、その値が大きいものを類似する記事として推薦します。
説明したアルゴリズムで算出した結果の一部をお見せします。2015年5月22日から6月3日に投稿された4つの記事と、それに類似度が高い記事3つです。
・ここ数年前から2015までのモダンフロントエンドを総まとめしてみた
1. JavaScriptにどのようなビジネス的メリットがあるか
2. 最近気になったGithub JavaScriptトレンド7選(2015年6月編)
3. okpの2015年振り返りと目標
・オフィスでリモートワーク
1. リモートで業務をする上で重要な3つのこと
2. リモートワーカーが気をつけたい運動不足と対策いろいろ
3. 日本のチームとリモートワークをした話@シリコンバレー
・受託開発において大切にしている3つのこと
1. 開発プロジェクトで利用しているタスク管理ツールについて
2. DDD Alliance!に参加して感じたソフトウェア設計と組織のあり方
3. チーム開発に必要な HRT
・Ruby on Railsのテストコード実装方針を考えた
1. Ruby on Rails で Web API のパラメータをバリデーションする
2. 開発用モックデータの作成方法で試行錯誤した
3. Rails開発で使っているオススメgemを5個(-1個)紹介します個人的には良い結果がでているのではないかと思うのですが、いかがでしょうか。
タイトルだけの判断になりますが、一番上の例では、フロントエンドを総まとめ に対して JavaScript 関連の記事が出ているのと、弊社フロントエンドチームのokpの記事が推薦されています。
その他の記事でどの程度の精度が出ているかは、実際にレコメンド機能が追加されてからのお楽しみということで…!
最後に、このレコメンドエンジンのアーキテクチャがどのようになっているかを説明します。簡単に概念図を書いてみました。実際には EC2 の前に ELB がいたり、EC2 は複数 AZ で冗長化されていたり…ですが、そのあたりは重要ではないので端折ってあります。
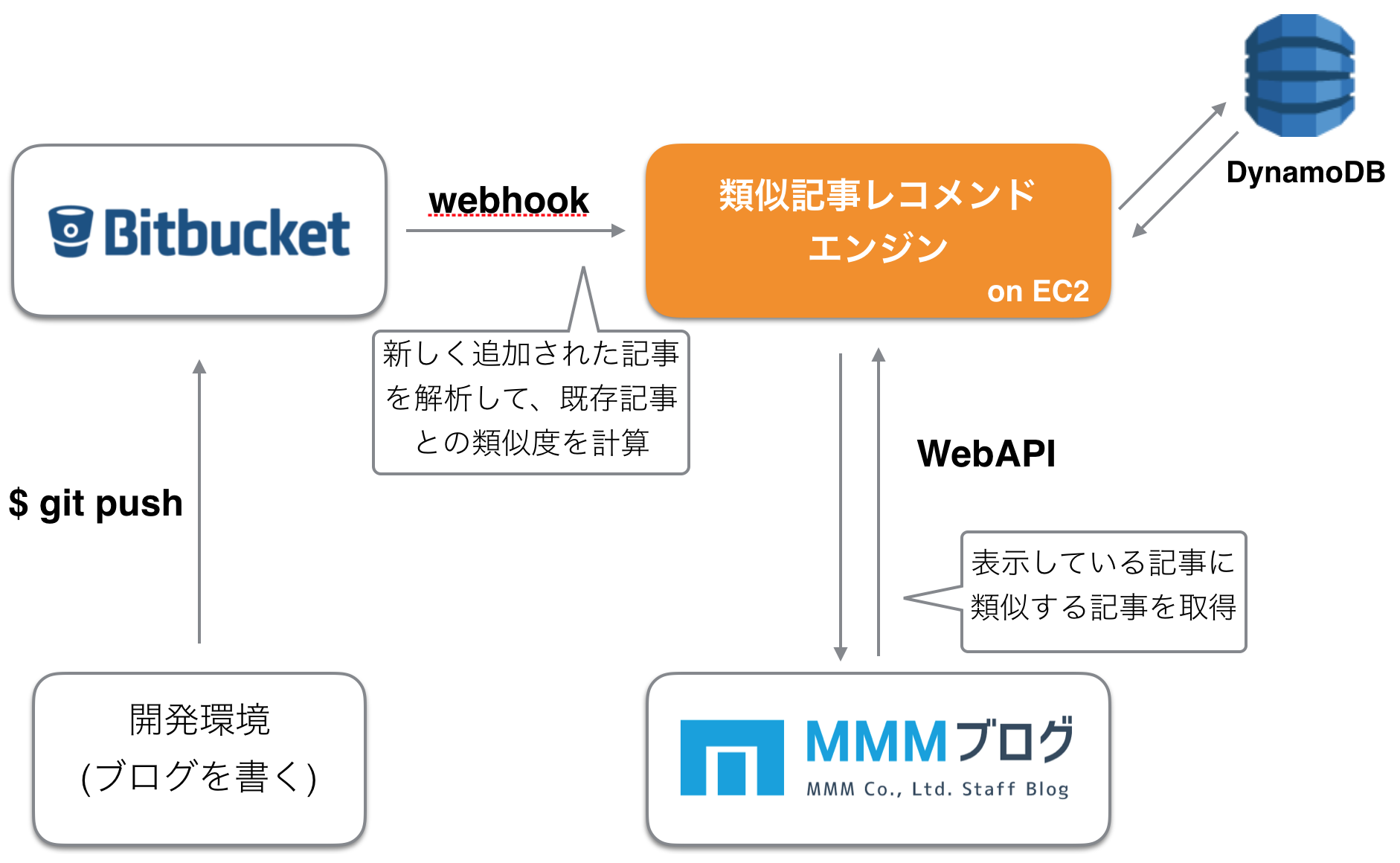
ブログ記事を書いて Bitbucket のレポジトリにプッシュすると、Webhook でレコメンドエンジンの API を叩きます。するとレコメンドエンジンは Bitbucket のブログ記事レポジトリを git pull して最新の記事を取り込んで解析し、既存の記事との類似度を計算した後、結果を DynamoDB に保存します。RDS を使わないで DynamoDB を使っている理由は特にないのですが、強いて言えば個人的に使ったことがなかったので練習で使ってみたかったことと、RDS を1台立てるよりは若干コストが低いかなと思うことの2点です。
新規記事の類似度計算バッチ処理はだいたい10~15秒程度で終わるため、別フローで走るブログのデプロイ処理が終わるよりも先に完了し、ブログが公開されるまでには類似度計算もバッチリ終わっている 想定 です。(未検証)
順調に行けば来週中ぐらいに社内レビューを通り、レコメンド機能がデプロイされるかと思いますので、ご期待ください!!
ビジネスを進化させるレコメンドシステムの開発をご希望の企業様は、是非MMMにご相談下さいませ!



