クラウド業界ニュースまとめvol.1 by MMM
mmmuser
デロイト トーマツ ウェブサービス株式会社(DWS)公式ブログ

どうも、Champ です 🙌
先日、髪の毛を青に染めたんですが、思った様に色が入らず、黒っぽい感じになっちゃいました 🥺
単に青色と言っても、色の濃さや薬剤につける時間など人に応じた調整が必要らしく、今回はその調整が微妙だったようです。。。
最近、AWS の機械学習サービスにハマっていて、毎日のようにいじくり回しているのですが、機械学習モデルもカラーリングと同じで、パラメータをいじって実験しているとどれが一番良かったか分からなくなっちゃいますよね😅
そこで今回は、Amazon SageMaker Model Registry について掘り下げてみたいと思います。こちらは、機械学習モデルの管理を効率化してくれるツールです!
簡単に言うと、機械学習モデルのライフサイクル管理をサポートする AWS のサービスです。主な機能としては:
モデルグループを作って、その中に複数のモデルバージョンを登録できます。
これにより、モデルの変更履歴をしっかり追跡できるわけです 。
ここで、ちょっと考えてみましょう。モデルのバージョン管理をしないと、どんな「つらさ」が待っているでしょうか?
機械学習モデルは複数作成し、性能の良いモデルを選ぶことは多々あるので適当な管理をしていたら大変なことになりそうですね。。。
それでは、具体的に SageMaker Model Registry で何ができるのか?
以下の5つのことが可能です。
モデルのバージョン管理だけでなく、クロスアカウントでの共有や承認ステータスの管理などもあり、一通りのことはできそうですね。
それでは、実際に SageMaker Model Registry にモデルを登録する手順を紹介します。
今回は簡単な scikit-learn モデルを作成して登録してみます。
詳細は省略しますが、デモ用に簡単な分類問題を解くトレーニングコードを生成しています。
import argparse
import os
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import joblib
import json
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--model-dir', type=str, default=os.environ['SM_MODEL_DIR'])
args, _ = parser.parse_known_args()
# テストデータの生成
np.random.seed(42)
X = np.random.rand(1000, 4)
y = (X[:, 0] + X[:, 1] > 1).astype(int)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルの学習
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# モデルの評価
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
# モデルの保存
joblib.dump(model, os.path.join(args.model_dir, 'model.joblib'))
# メトリクスの保存
with open(os.path.join(args.model_dir, 'metrics.json'), 'w') as f:
json.dump({"accuracy": accuracy}, f)詳細な手順は割愛しますが、Sagemaker Studio Domainを作成した後、任意のユーザでログインし、下記画面からノートブックを作成します。
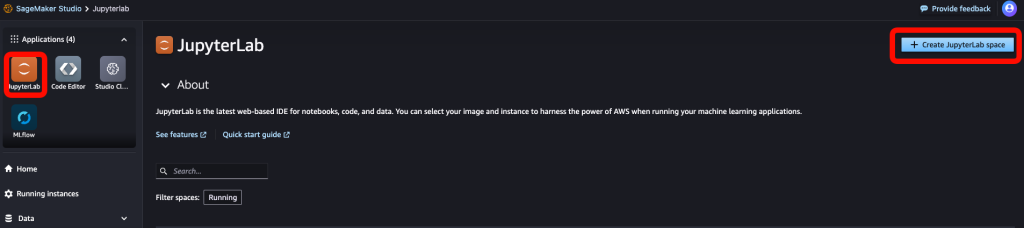
以降の手順ではノートブックに記述するコードを記述します。
import sagemaker
from sagemaker import get_execution_role
from sagemaker.sklearn.estimator import SKLearnsagemaker_session = sagemaker.Session()
role = get_execution_role()
下記の様なレスポンスが得られればOKです。

role = get_execution_role()
sklearn_estimator = SKLearn(
entry_point='train.py',
role=role,
instance_type='ml.m5.large',
framework_version='0.23-1',
py_version='py3',
instance_count=1
)
sklearn_estimator.fit()上記のコードでは SKLearn エスティメータを設定しています。これは、scikit-learn を使用したモデルのトレーニングジョブを定義します。
sklearn_estimator.fit()model_metrics = ModelMetrics(
model_statistics=MetricsSource(
s3_uri=f'{sklearn_estimator.output_path}/{sklearn_estimator.latest_training_job.job_name}/output/metrics.json',
content_type='application/json'
)
)上記のコードでは、トレーニング中に生成されたメトリクスファイルの S3 パスを指定しています。
model = Model(
image_uri=sklearn_estimator.image_uri,
model_data=sklearn_estimator.model_data,
role=role,
sagemaker_session=sagemaker_session
)model.register(
content_types=['text/csv'],
response_types=['text/csv'],
inference_instances=['ml.t2.medium', 'ml.m5.large'],
transform_instances=['ml.m5.large'],
model_package_group_name='SKLearnModelPackageGroup',
model_metrics=model_metrics
)上記のコードは、トレーニングされたモデルを SageMaker Model Registry に登録するためのものです。
各パラメータの説明は以下の通りです:
これらのパラメータを設定することで、モデルの使用方法や制約、性能などの情報を Model Registry に記録し、後でモデルを簡単に検索、比較、デプロイできるようになります。
Sagemaker StudioのModelsに以下の様に登録されていればOKです。
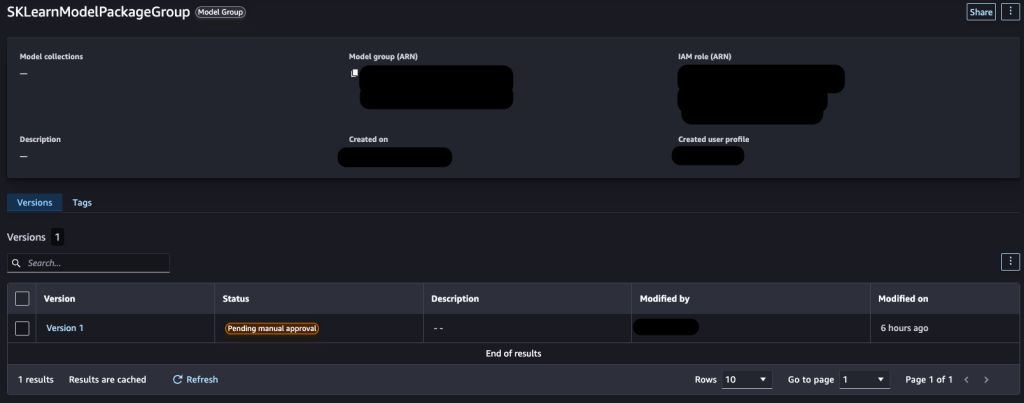
手順は以上です。
SKLearn クラスの fit メソッドで output_path を指定していなくても実行できる理由は、SageMaker が自動的にデフォルト S3 バケットを設定するためです。
以下に詳細を説明します:
明示的にバケットを指定しておらず、Sagemaker 用デフォルト S3 バケットが存在しない場合、デフォルトの S3 バケットが自動的に生成されます。
このバケット名は通常、sagemaker-{リージョン}-{アカウントID}の形式になり、明示的に指定しない場合はこの S3 バケットにモデルアーティファクトを保存します。
トレーニングジョブごとに一意のプレフィックスが自動的に生成されます。このプレフィックスはトレーニングジョブ名に基づいています。
この機能により、ユーザーは出力パスを明示的に指定しなくても、SageMaker でモデルのトレーニングと保存を行うことが可能です。
さて、モデルを登録した後、Model Registry の画面を確認すると、「Container」という項目があるのに気づきました。「えっ?コンテナなんて指定してないのに...」って思いませんでした?
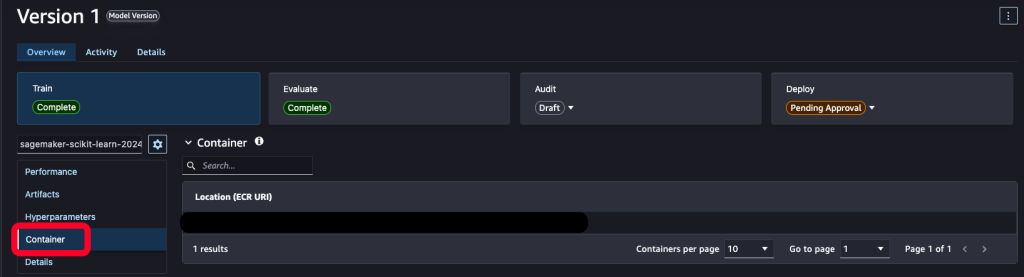
実は、これが SageMaker の便利なところなんです。
SageMaker はコンテナベースのアプローチを採用していて、モデルを登録する際に自動的にコンテナ情報を含めてくれます。
でも、なぜコンテナが必要なのでしょうか?
つまり、コンテナのおかげで、モデルの再現性と移植性が確保され、デプロイや推論が簡単に実現できるというわけです。
SageMaker Model Registry を使うと、モデルのバージョン管理やメタデータの追跡、承認ステータスの管理が本当に楽になります。特に大規模なプロジェクトや、複数のチームが関わるプロジェクトでは重要な機能です。
今回は基本的な使い方と、ちょっとした裏側の仕組みを紹介しましたが、次回は SageMaker Pipelines と Model Registry を組み合わせた自動デプロイの方法について深掘りしてみようと思います。
それでは、ここまで読んでくださりありがとうございました。
また次回お会いしましょう 👋



