AWS Healthからの通知をBedrockに解釈させて運用負荷を下げる
keichan
デロイト トーマツ ウェブサービス株式会社(DWS)公式ブログ

最近TypeScriptにハマっているmickeyです。今回は、先月に社内ハッカソンで作成した、社内案件レコメンド用システムについて紹介したいと思います(幸いにも、今回はチームでgene賞を受賞しました)。前回のハッカソンは入社して間もない頃で、個人的に「次回のハッカソンがあれば参加したいな」と思っていました。そんな中、データ分析勉強会で一緒だったakaを「ハッカソンに一緒に参加しませんか」と誘ったところ、快く了承してくれたため、第3回社内ハッカソンではakaとチームを組んで参加することにしました (社内で呼びかけるとすぐに承諾してくれるメンバーがいるのがDWSの良いところです)。今回は、ハッカソンで作成した案件レコメンド用システムの詳細をご紹介します。
まず「今のDWSにとって何を作るのが良いだろうか」という議論をチームで行いました。その中で、プリセールスチームから「案件に適したメンバーをアサインするための指標が欲しい」という声が上がっていたのを思い出し、それをシステムとして実現することが良いのでは、と考えました。結果複数のアイデアが提案されましたが、その中で最も実用的だと思われる上記の案を選び、制作を開始しました。
我々は、普段使用しているコミュニケーションツールであるSlackを活用して、Slack botによるシステムを作成することにしました。システムの大まかな流れとして、Slack botを起動し、案件名と詳細を入力するフォームを提供しその情報を送信した後、社内メンバーの中から案件に適していると判断された上位5名のメンバーが回答として返ってくる仕組みを想定しました。
次に、レコメンド部分について検討しました。まず、レコメンドを行う上で重要なのはメンバーごとの情報です。DWSでは社内のドキュメントが豊富にあり、「メンバーの知識領域」や全メンバーの「自己紹介・他己紹介」が記載されたドキュメントが存在します。そのため、これらのドキュメントをレコメンドに使用することにしました。
肝心のレコメンドに使用するサービスですが、当初はAmazon Comprehendを使用し、文書からキーフレーズ抽出やトピックモデリングを行うことを考えていました。しかし、以下の理由から、LLM(Large Language Model)を使用したサービスであるBedrockを活用することにしました。
また、「自己紹介・他己紹介」ドキュメントを情報源として活用することで、以下の相乗効果が起こることが期待されました。
このような効果も狙いとして、大まかな方針を上記の通りに定め開発を進めていくことにしました。
ここからは、実際に作成したものの紹介になります。
システムのアーキテクチャ図は以下になります。
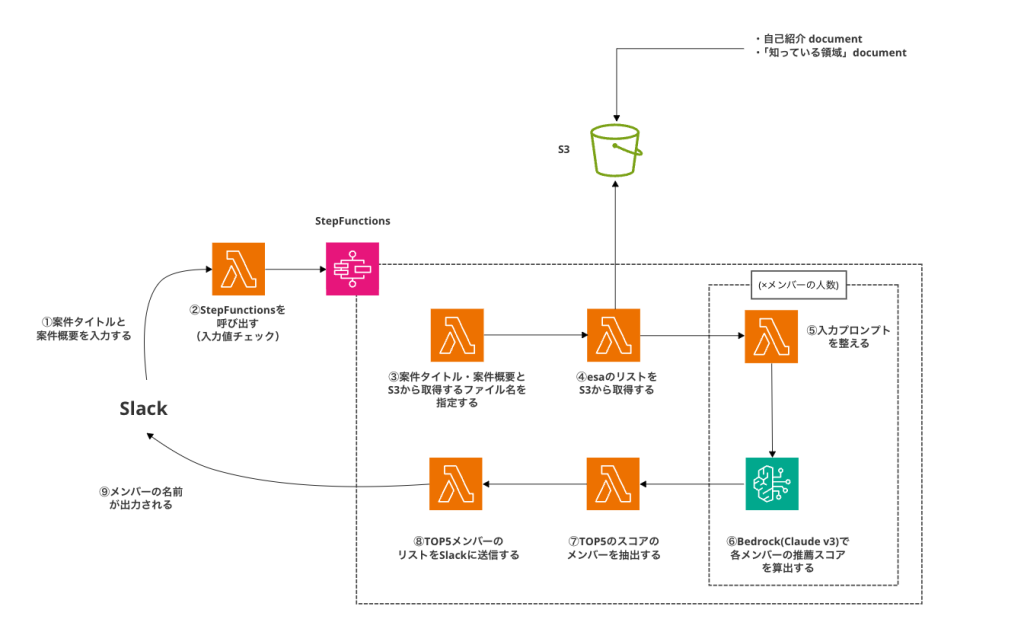
Bedrockで使用するLLMとして、ちょうどこの開発時期に最高性能のナレッジベースの「Claude 3 Sonnet」が利用可能になったことから、そちらを採用することにしました。
Bedrockでの推論内容ですが、各ドキュメントと入力された案件情報とから、①技術力、②案件の要件と人材のスキルマッチ度、③その人の熱意の評価、④人材の過去の実績と案件の要求との関連度を含めた総合評価を行い、100点満点でスコアを算出するように設定しました。特に、技術力のみでレコメンドをさせエンジニア歴が長くスキルが豊富にある人が頻出するより、経験は浅いけれども熱意がある人も上位に出現する可能性を向上させる為、熱意の評価という欄を設け、インプットされたデータ内から熱意を読み取れる箇所を取り込めるようなシステムにしました。
また、DWSメンバー約50名に対して同時に個別のプロンプトを実行しその結果を集計するために、Step Functionsを適切なサービスとして選定しました。
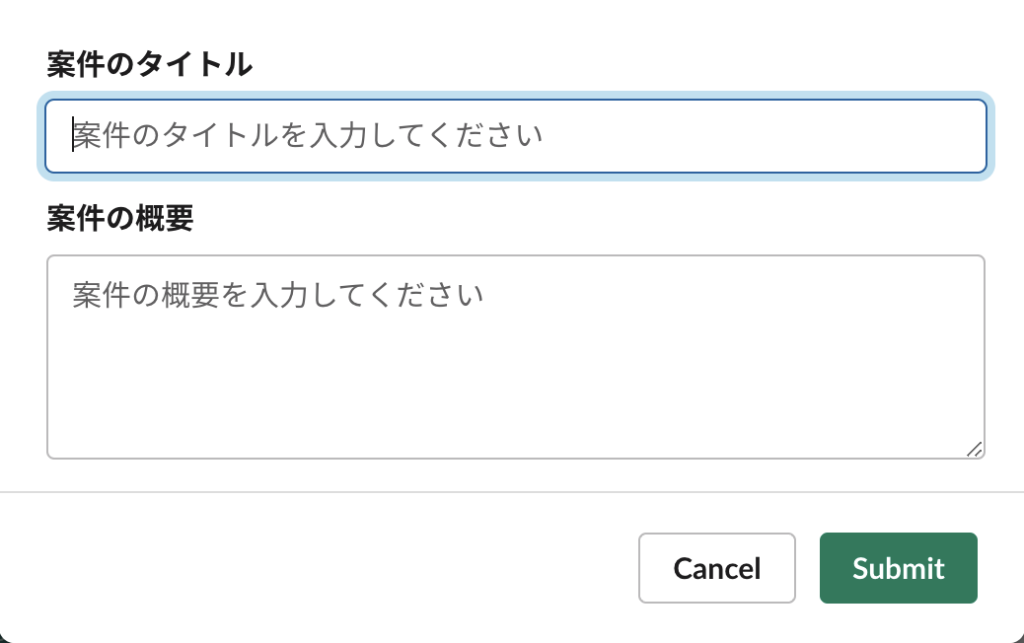
詳細は省略しますが、Slack botには案件名と案件の概要を入力できるようなフォームが表示されます。ユーザーはここに必要な情報を入力し、約20秒後にSlackにTOP5のメンバーが出力される仕組みとなっています。
今回のハッカソン作成で、技術的に感じたことは以下の通りです。
Step Functionsの多性能性
Amazon ComprehendとBedrockの違い
今後の展望として以下が考えられます。
業務が忙しく思ったよりもなかなかハッカソンに取り組む時間が取れなかった時期もありましたが、最後に成果物として形になったときは、何物にも代えがたい達成感を感じました。また、今後、LLMの進化に伴い、推薦の精度や機能の幅も広がっていくものと期待しています。開発期間約1ヶ月を含めて、非常に楽しいハッカソンとなりました。一緒に開発してくれたakaに感謝します。全てのチームがアイデア豊富なハッカソンで、他のチームの発表を聞くだけでも楽しかったです。非常に素晴らしい社内ハッカソンでした!
ここまで読んでいただいたみなさん、ありがとうございました。