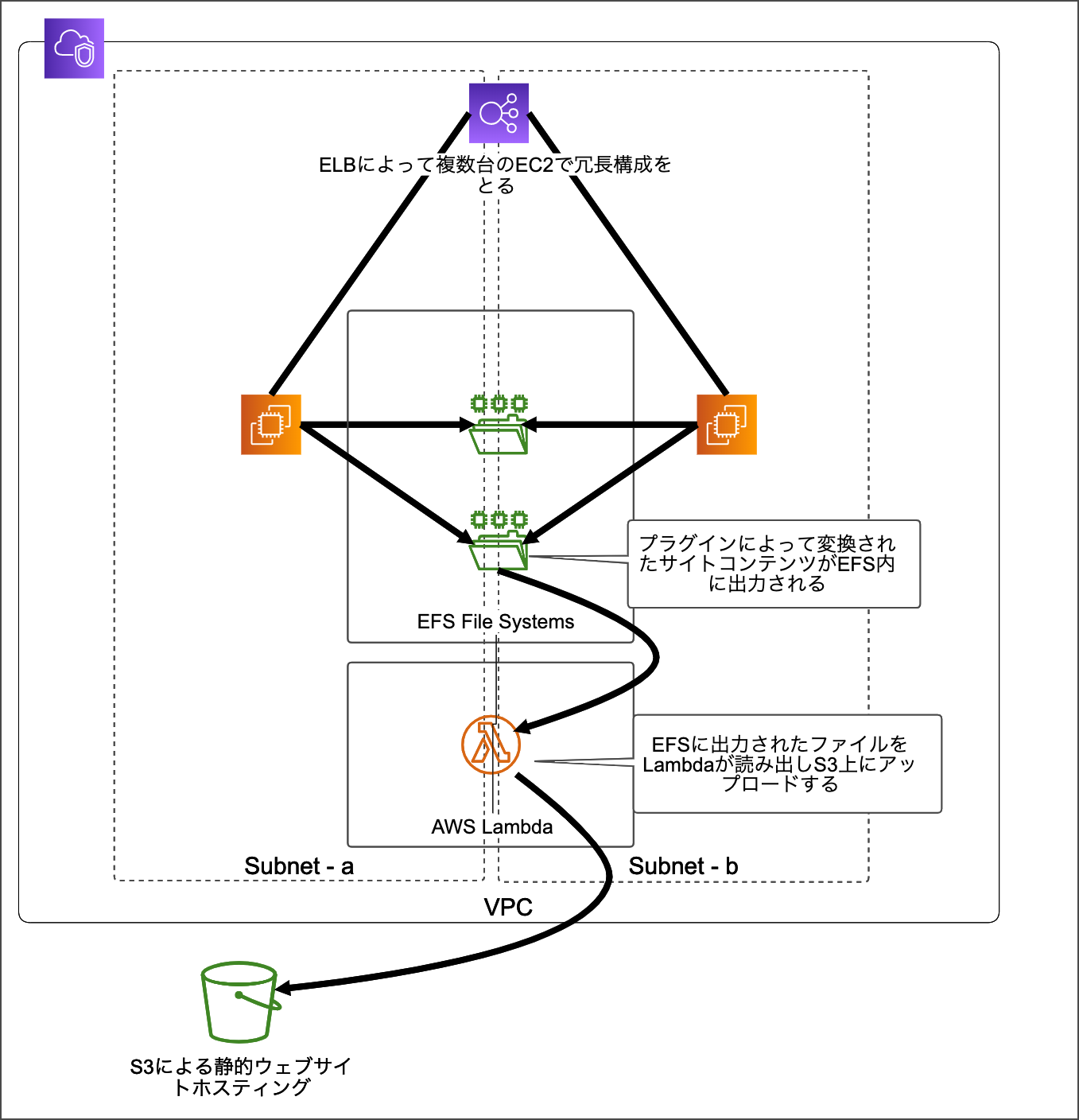
AWSの新機能「AWS LambdaのEFS連携」を早速検証しました
sho
デロイト トーマツ ウェブサービス株式会社(DWS)公式ブログ

今週、 AWS Systems Manager(SSM) の Session Manager で踏み台用のEC2インスタンスにつながらなくなる障害が2件立て続けに発生した。
それぞれ原因が違っており、復旧に手間取ってしまったため、今回は備忘録も兼ねて状況と対応策について整理してまとめておきたいと思う。
No space left on device1件目の障害は下記のような状況だった。
AWSのマネジメントコンソールから Session Manager で接続しようとすると、ボタンは押せるものの…
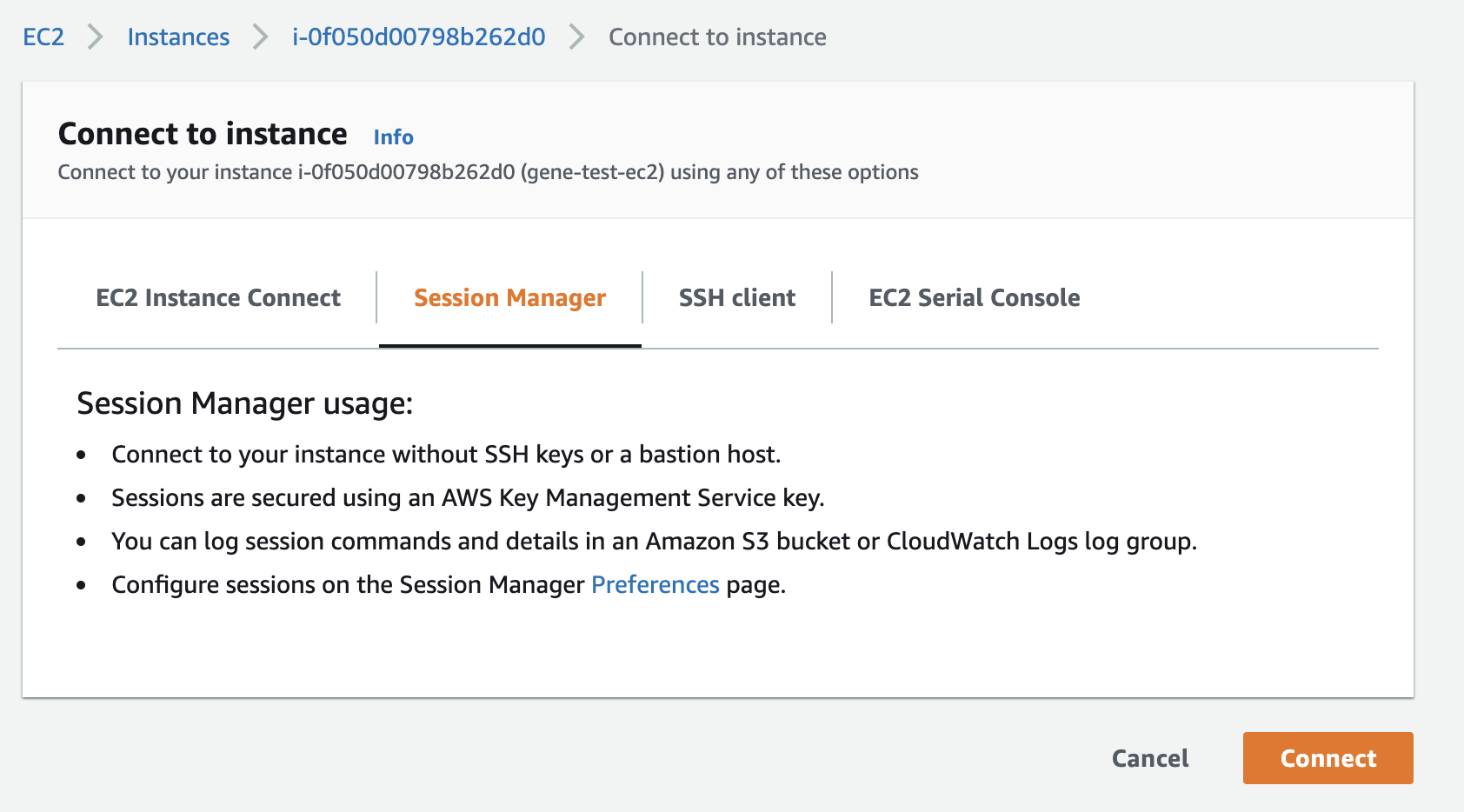
下記のような状態で、いつまで経ってもプロンプトが返ってこない状態だった。

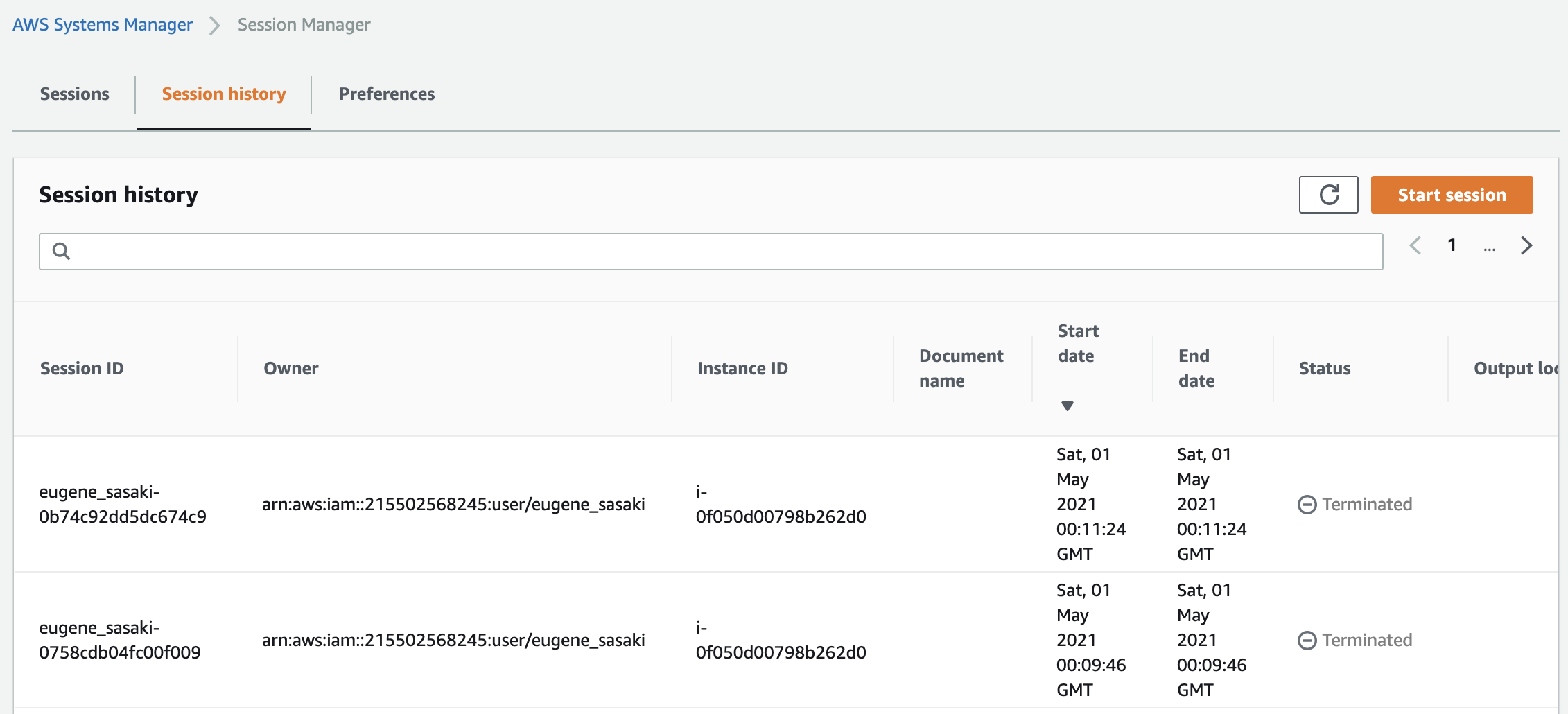
SSMの Session History から確認すると、 Start date と End date が同じ時間になっており、 Status が Terminated となっていた。
取り急ぎ、インスタンスの再起動を行ってみたものの、現象は改善されず。
下記の画像の通り、 Actions -> Monitor and troubleshoot -> Get system log からログを確認すると…

No space left on device
と出ていた。
ディスクの使用率が100%になってしまっていたことが原因だった。
ディスクはデフォルトの8GBとしか割り当てていなかったため、EBSを拡張する必要がある。
該当のEBSから Modify Volume を選択する。
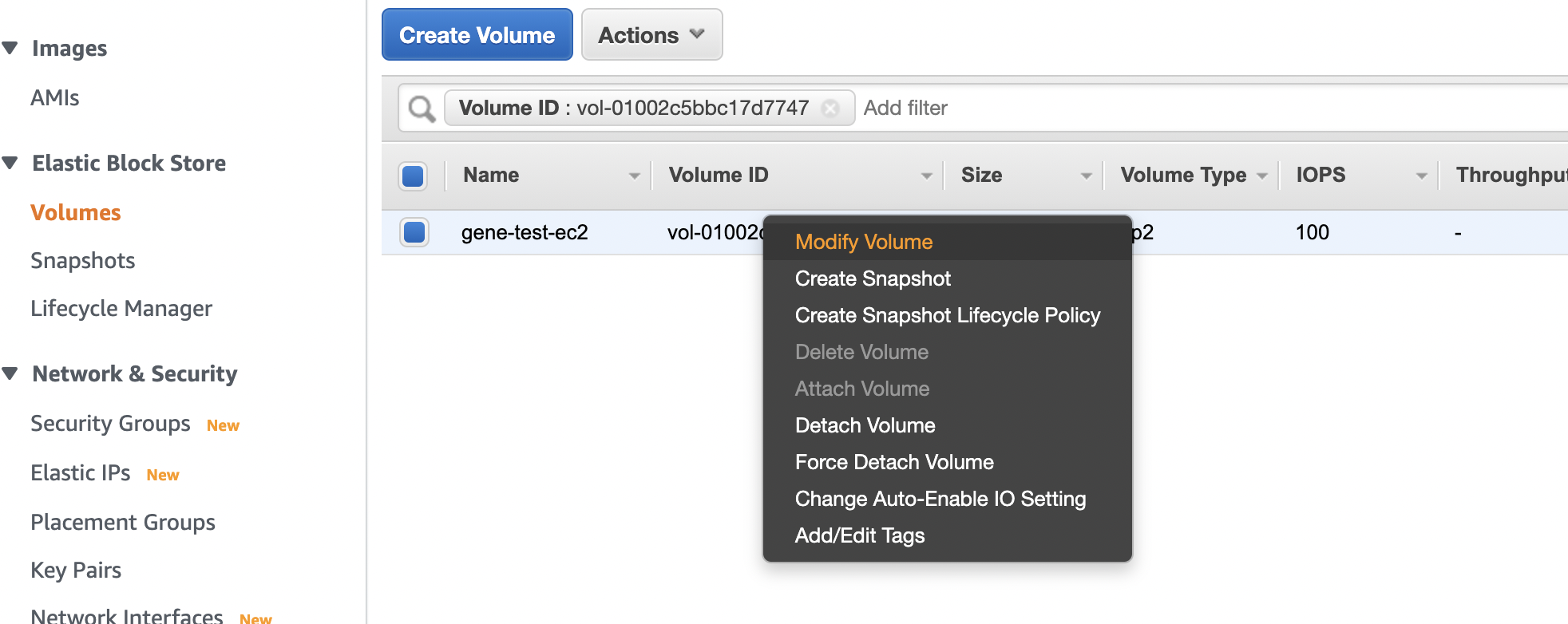
サイズを変更する。今回は再現環境のため、9GBにした。
Yes を押す。
EBS ボリュームのサイズを増やしたら、ファイルシステムを拡張する。
【参考】
ボリュームサイズ変更後の Linux ファイルシステムの拡張
ディスクがフルの状態になっている踏み台EC2インスタンスでは作業ができないので、作業用のEC2インスタンスを立ち上げ、そちらにフルになったEBSをアタッチして、作業を行う。
Detach Volume でデタッチする。
次に、作業用のEC2インスタンスへ該当のEBSをアタッチする。
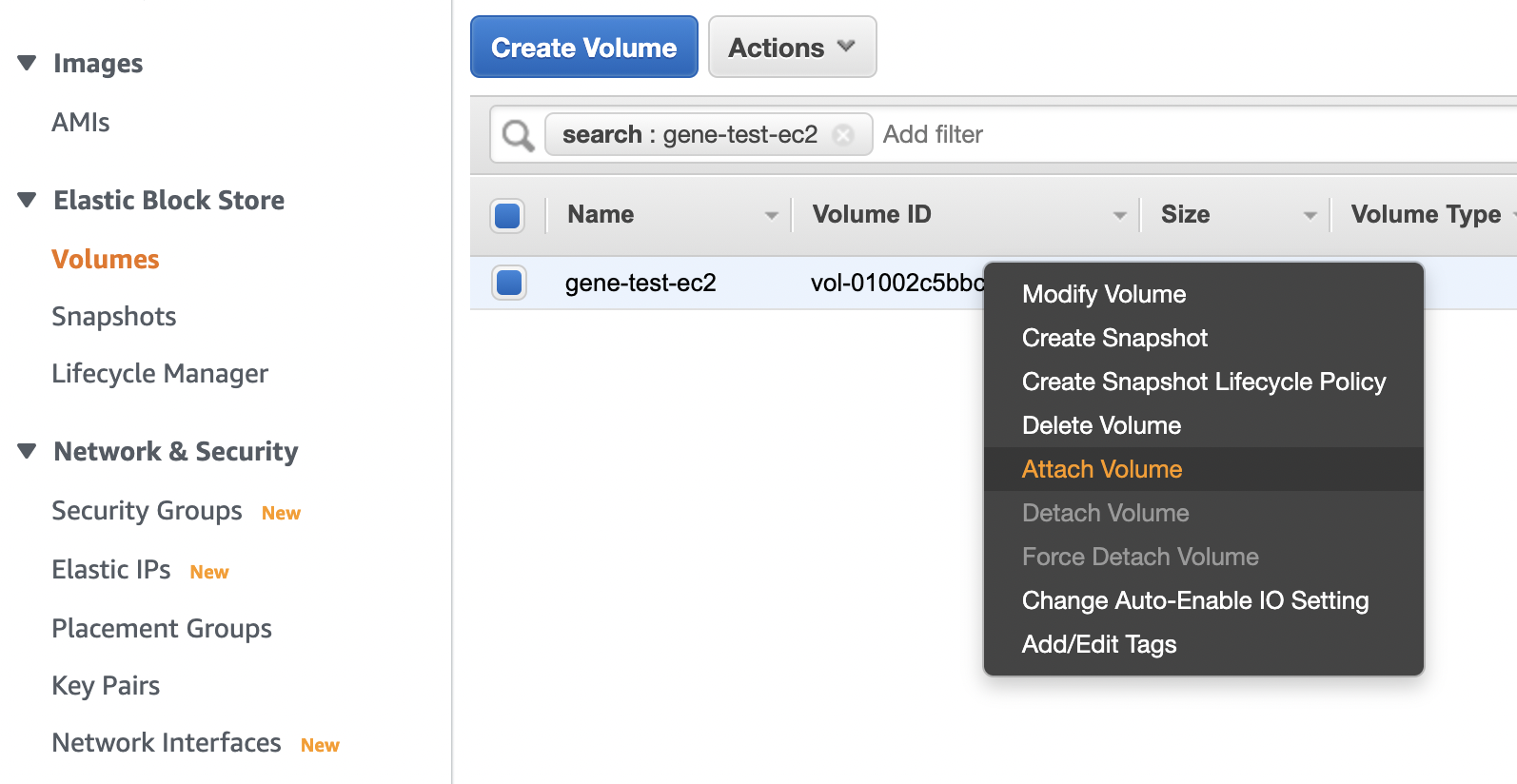
作業用のEC2インスタンス gene-tmp-ec2 へアタッチ。
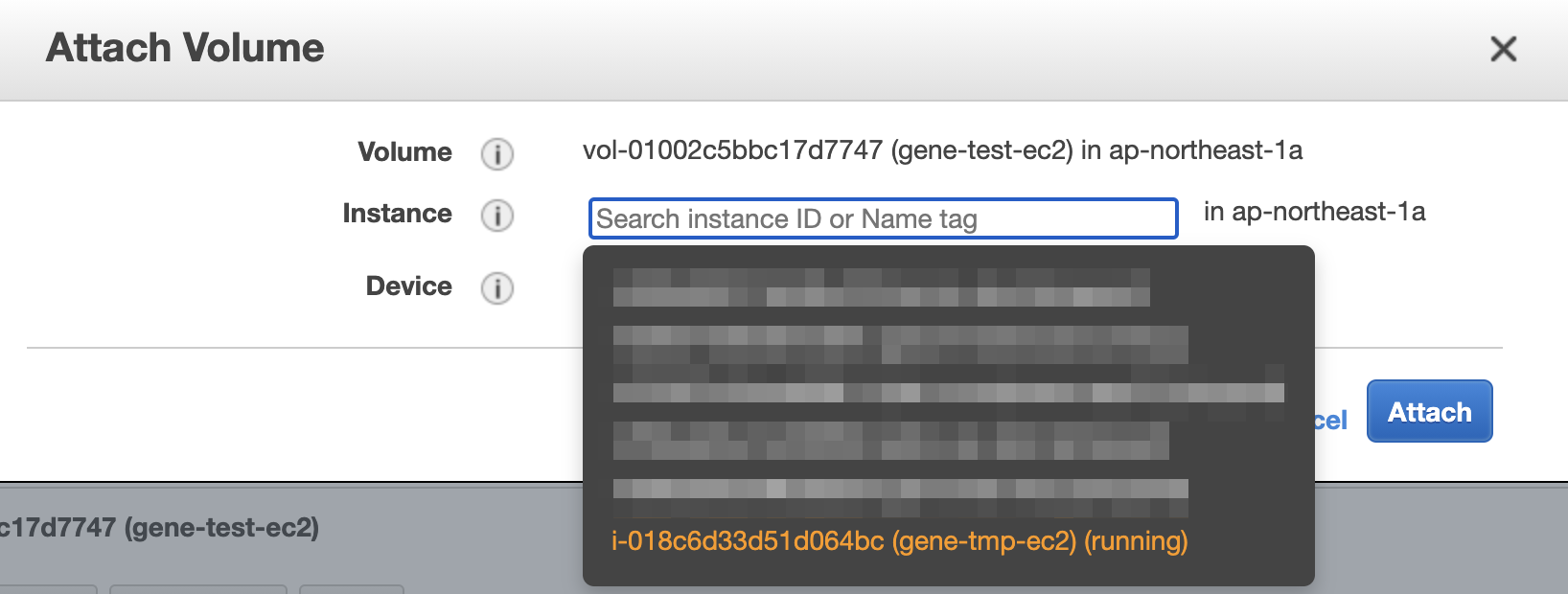
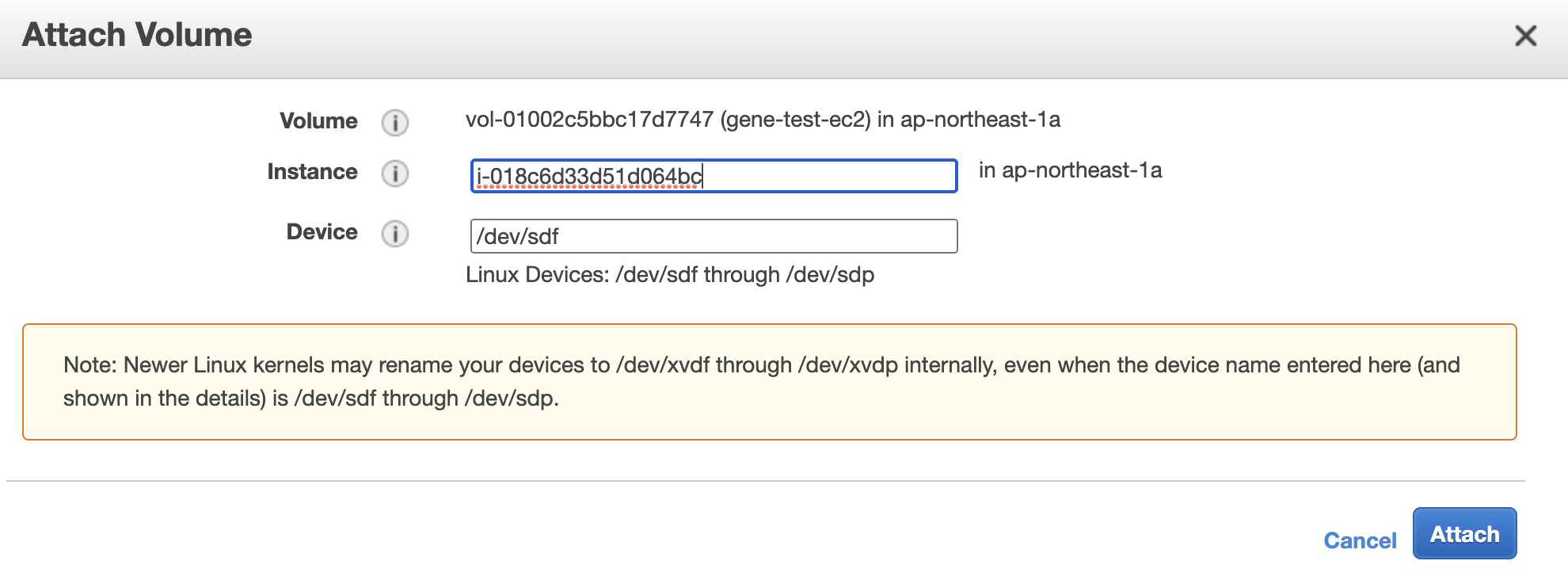
Attach をクリック。
作業用のEC2インスタンスに Session Manager で接続して作業開始。
lsblk コマンドを使用して、インスタンスにアタッチされているデバイスに関する情報を表示する。
[root@ip-172-31-27-241 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 8G 0 disk
└─xvda1 202:1 0 8G 0 part /
xvdf 202:80 0 9G 0 disk
└─xvdf1 202:81 0 8G 0 partデバイスを mount コマンドで /mnt へマウントする。
[root@ip-172-31-27-241 ~]# mount -t xfs -o nouuid /dev/xvdf1 /mnt先程マウントした /mnt の使用率が100%になっていることが確認できる。
[root@ip-172-31-27-241 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 482M 0 482M 0% /dev
tmpfs 492M 0 492M 0% /dev/shm
tmpfs 492M 440K 492M 1% /run
tmpfs 492M 0 492M 0% /sys/fs/cgroup
/dev/xvda1 8.0G 1.5G 6.6G 18% /
tmpfs 99M 0 99M 0% /run/user/0
/dev/xvdf1 8.0G 8.0G 20K 100% /mntgrowpart コマンドで、パーティションを拡張する。
[root@ip-172-31-27-241 ~]# growpart /dev/xvdf 1
CHANGED: partition=1 start=4096 old: size=16773087 end=16777183 new: size=18870239 end=18874335再度 lsblk コマンドで確認。1番下の行のSIZEが8GBから9GBになっていることが確認できる。
[root@ip-172-31-27-241 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 8G 0 disk
└─xvda1 202:1 0 8G 0 part /
xvdf 202:80 0 9G 0 disk
└─xvdf1 202:81 0 9G 0 part /mntxfs_growfs コマンドでファイルシステムを拡張する。
[root@ip-172-31-27-241 ~]# xfs_growfs -d /mnt
meta-data=/dev/xvdf1 isize=512 agcount=4, agsize=524159 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1 spinodes=0
data = bsize=4096 blocks=2096635, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
data blocks changed from 2096635 to 2358779df コマンドで見てみると、 /mnt の使用率が100%から89%になったことを確認。
[root@ip-172-31-27-241 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 482M 0 482M 0% /dev
tmpfs 492M 0 492M 0% /dev/shm
tmpfs 492M 440K 492M 1% /run
tmpfs 492M 0 492M 0% /sys/fs/cgroup
/dev/xvda1 8.0G 1.5G 6.6G 18% /
tmpfs 99M 0 99M 0% /run/user/0
/dev/xvdf1 9.0G 8.0G 1022M 89% /mntあとは、該当のEBSを元の踏み台EC2インスタンスへアタッチしなおせば起動する。
正常に Session Manager で接続できることを確認して、作業終了。
no EC2 instance role found2件目の現象としては、下記のようにAWSのマネジメントコンソールから Session Manager で接続しようとすると Connect ボタンが押せなくなっていた。
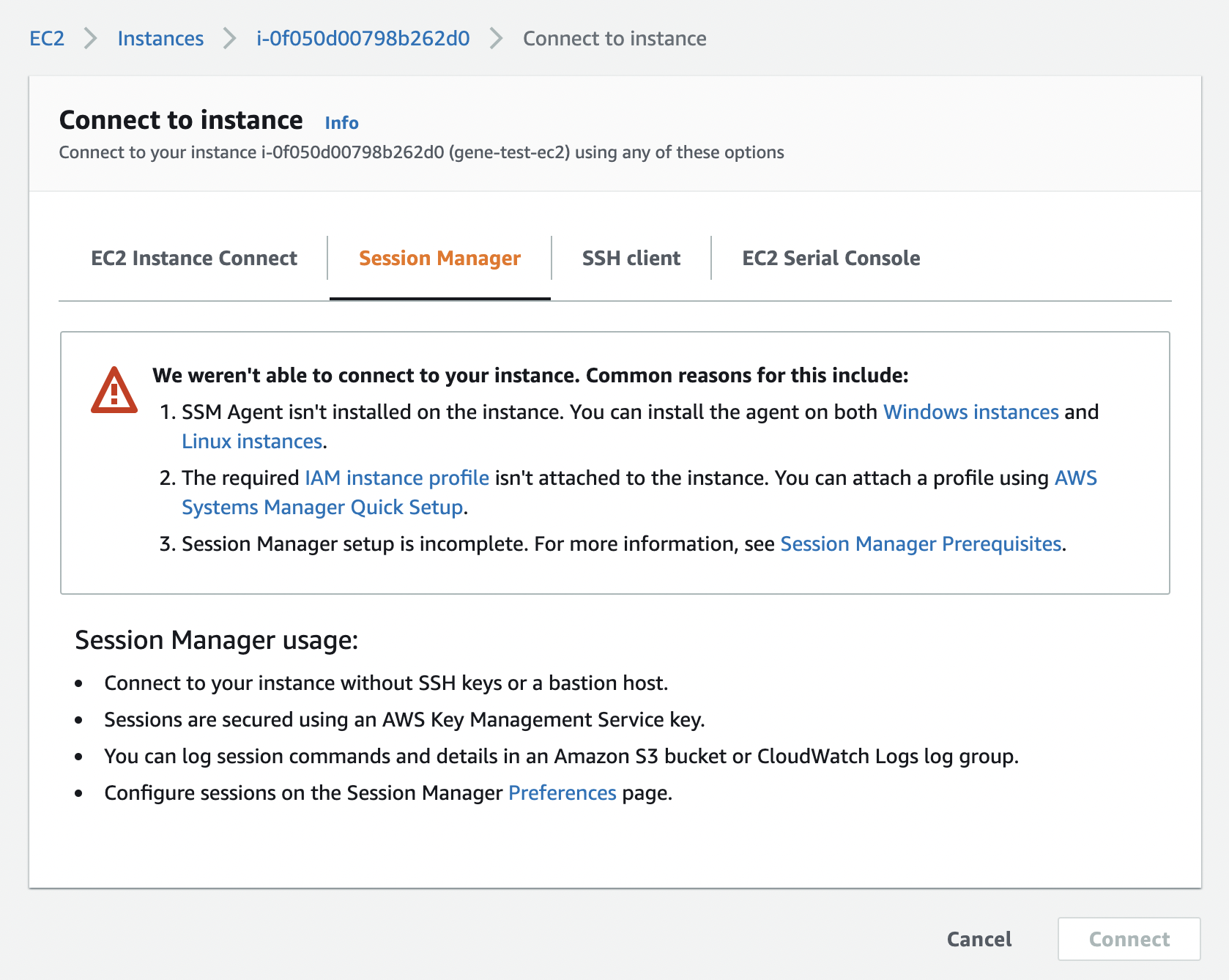
1件目と同様に、ログを確認するも正常に起動しているように見えた。
SSMエージェントも正常に起動しているログが出ていた。
なんとか別のEC2インスタンスから、SSH接続してログなどを確認して見ると
/var/log/amazon/ssm/hibernate.log に The security token included in the request is invalid. と出ていたり…
[root@ip-172-31-23-250 ~]# cat /var/log/amazon/ssm/hibernate.log
2021-05-01 02:08:51 ERROR Health ping failed with error - UnrecognizedClientException: The security token included in the request is invalid.
status code: 400, request id: e77970b7-576c-42b2-ad40-faeed8b0fd2a/var/log/amazon/ssm/amazon-ssm-agent.log に no EC2 instance role found など見慣れないログが出ていた。
2021-05-01 02:27:54 INFO [ssm-agent-worker] Entering SSM Agent hibernate - EC2RoleRequestError: no EC2 instance role found
caused by: EC2MetadataError: failed to make EC2Metadata request
status code: 404, request id:
caused by: <?xml version="1.0" encoding="iso-8859-1"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>404 - Not Found</title>
</head>
<body>
<h1>404 - Not Found</h1>
</body>
</html>ログから推測すると、どうもEC2インスタンスにアタッチしている IAM Role まわりが怪しいそうだ、と判断。
という手順を行ってみたところ、正常に Session Manager で接続できた。
関係者に確認してみると、 Terraform で作業中に、IAM Roleの再作成が行われていたようだ、とのことだった。
今回、再現環境を構築して試してみたところ、EC2インスタンスが起動中でも、アタッチされているIAM Roleは削除可能だった。
また、削除後に同じ名前でIAM Roleを作成することもできるため、EC2側のコンソールを見ると正常にIAM Roleがアタッチされているに見えてしまうこともわかった。
おそらく今回のケースでは、EC2インスタンスが削除される前のIAM Roleを参照し続けており正常なオペレーションが行えない状態だったと思われる。
障害が発生しているときは、どうしても復旧を急ぐあまり、焦ってしまいがち。
同じような現象が発生してもすぐに対応できるように、対応などをしっかりと整理してまとめておくのは重要なことだと思っている。
今回の情報がどこかで役に立つと嬉しい。