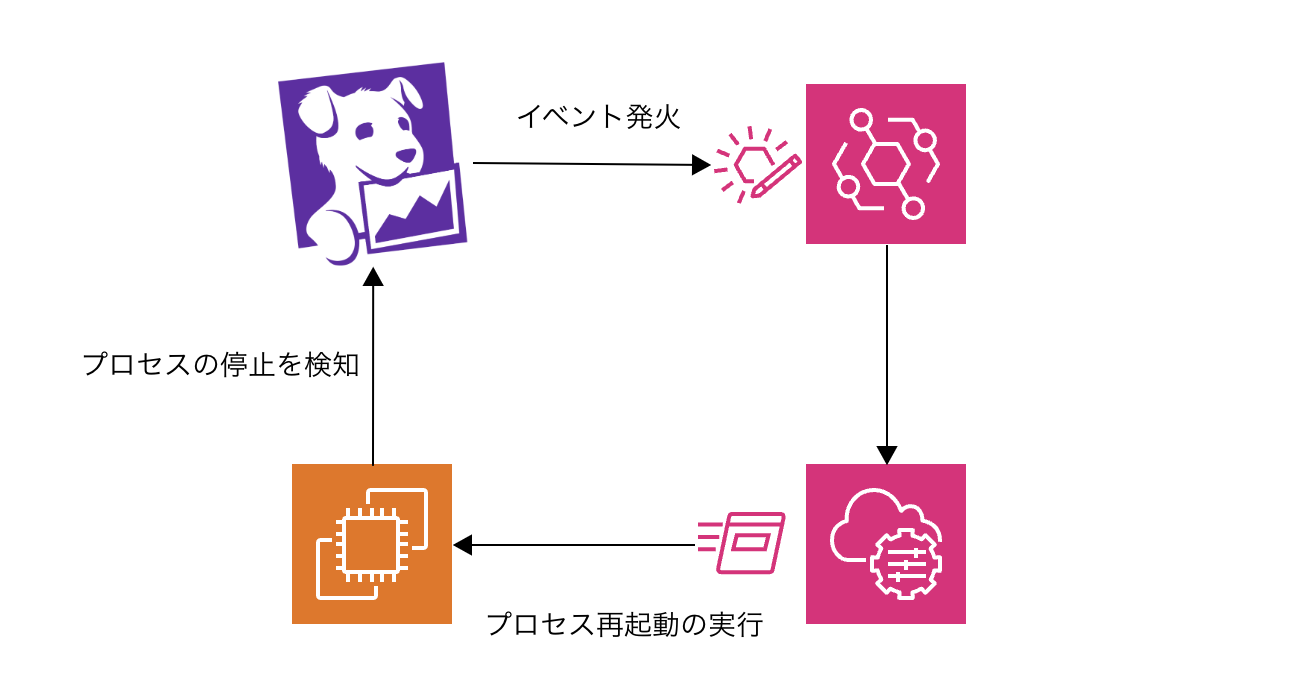
Datadog × EventBridge でプロセス自動再起動を実装してみた
yuhan
デロイト トーマツ ウェブサービス株式会社(DWS)公式ブログ
re:InventでさまざまなAWSの新サービスが発表されましたが、機械学習モデルの開発、学習、メンテナンスのライフサイクルに使える、Amazon SageMakerもありました。また、Amazon Rekognition VideoやAWS DeepLens、Amazon ComprehendなどのAIサービスもいくつか発表されています。
機械学習導入への需要が高まる中、今回は、Amazon Machine Learningを実際に使用しながら、東京都の不動産の取引価格を予測してみたので、ご紹介させていただきます。
Amazon Machine Learningとは、データ解析の専門的な知識がなくても機械学習によるデータ分析が行えるAWSマネージドサービスです。データ統計やモデルの作成、評価、予測などで手間のかかる部分を自動化してくれます。
現在利用できる学習アルゴリズムには以下があります。
入力値データを2つの選択肢のどちらかに分類します。
例.このEメールはスパムか否か?
入力値データを3つ以上の選択肢のうちいずれかに分類します。
例.顧客が興味を示す製品のカテゴリはどのカテゴリ?
値の予測を行います。
例.明日のシアトルの温度は何度?
機械学習の元の定義は、
the field of study that gives computers the ability to learn without being explicitly programmed.
というのが有名で、「明示的なプログラミングをせず、コンピューターに学習能力を持たせる学問」とのことです。言い換えると、過去のデータを元に将来の予測を行う分析手法で、活用例としては以下のようなものが考えられます。
従来は人力でデータ分析を行なっていましたが、機械学習により分析、モデル生成を行い、分析結果も自動で算出してくれます。これにより、既存のデータを活用して、よりビジネス価値のある判断を下しやすくなります。
Amazon Machine Learningを使うと、この機械学習モデルを自作することなく、素早く実装を行うことができるのが特徴です。
今回は、Amazon Machine Learningを使って、東京都の不動産の取引価格を予測するモデルを作成しましたので、その紹介をしていこうと思います。
国土交通省土地総合情報システムのデータを使用し、東京都の不動産の取引価格を予測します。
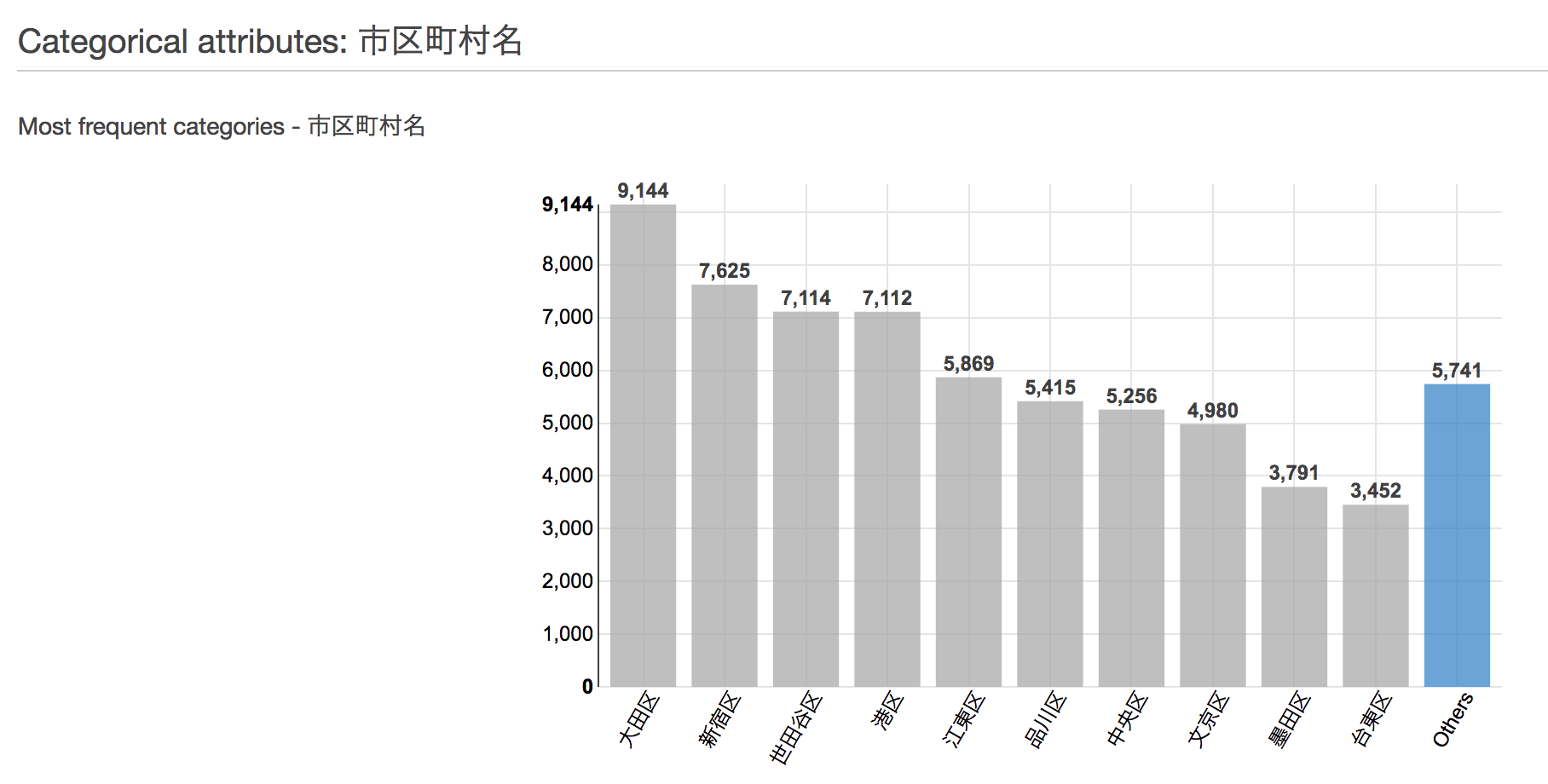
今回は、平成17年第3四半期から平成29年第2四半期までの、東京都の全市区町村のデータを使用しました。データの内容例としましては、以下のようになっています。
No|種類|地域|市区町村コード|都道府県名|市区町村名|地区名|最寄駅:名称|最寄駅:距離(分)| **取引価格(総額)** |坪単価|間取り|面積(㎡)|取引価格(㎡単価)|土地の形状|間口|延床面積(㎡)|建築年|建物の構造|建物の用途|今後の利用目的|前面道路:方位|前面道路:種類|前面道路:幅員(m)|都市計画|建ぺい率(%)|容積率(%)|取引時点|備考
--|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|--
1|中古マンション等|商業地|13101|東京都|千代田区|一番町|半蔵門|3| **64000000(ターゲット)** |2500000|2LDK|55|740000|ほぼ正方形|6.4|500|昭和47年|SRC|住宅|住宅|北東|区道|4|第1種住居地域|60|400|平成29年第2四半期|改装済を購入この中から、データ量が少ないものや、意味を持たないカラムを除外して、最終的に以下のようなデータに整形をしました。データの数は全部で約6万件となります。
種類|都道府県名|市区町村名|地区名|最寄駅:名称|最寄駅:距離(分)| **取引価格(総額)** |間取り|面積(㎡)|建築年|建物の構造|建物の用途|今後の利用目的|都市計画|建ぺい率(%)|容積率(%)|取引時点
--|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|--
中古マンション等|東京都|千代田区|一番町|半蔵門|3| **64000000(ターゲット)** |2LDK|55|昭和47年=>西暦に変換|SRC|住宅|住宅|第1種住居地域|60|400|平成29年第2四半期=>西暦に変換CSVをS3バケットにアップロードして、データの準備は完了です。
Amazon Machine Learningではデータソースというオブジェクトがあります。
ここに入力データに関する情報を定義できて、S3にアップしたCSVの場所、スキーマ、ターゲットなどを設定してゆきます。取引価格(総額)を予測したいので、ターゲットに設定します。
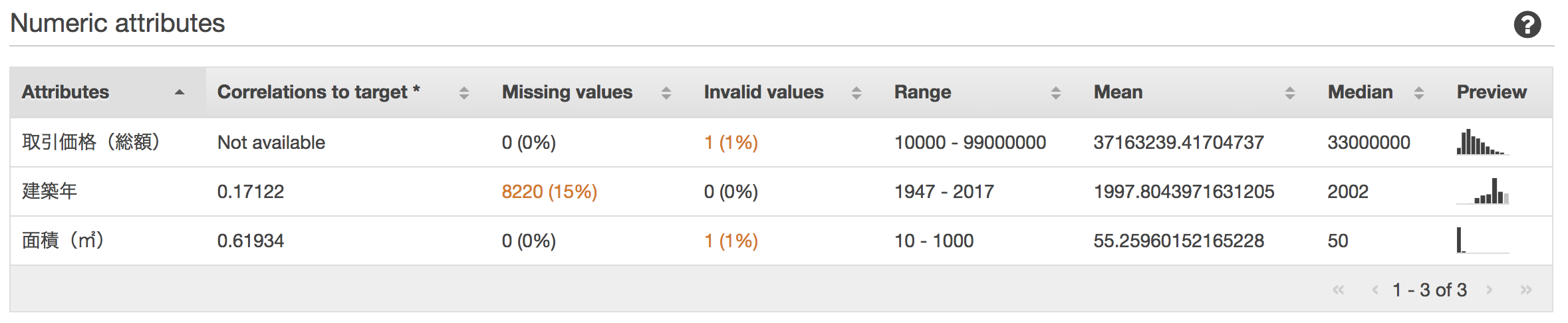
スキーマは、ひとまず、Amazon ML側でサジェストされた型を採用しました。5つの項目が数値型となっており、その他はカテゴリ型になっています。
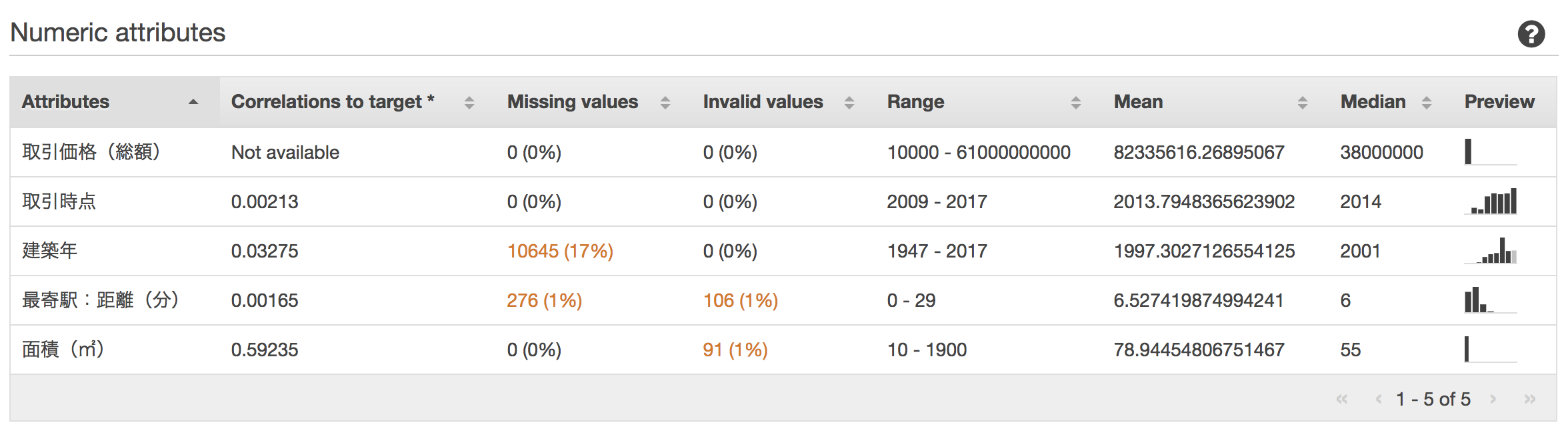
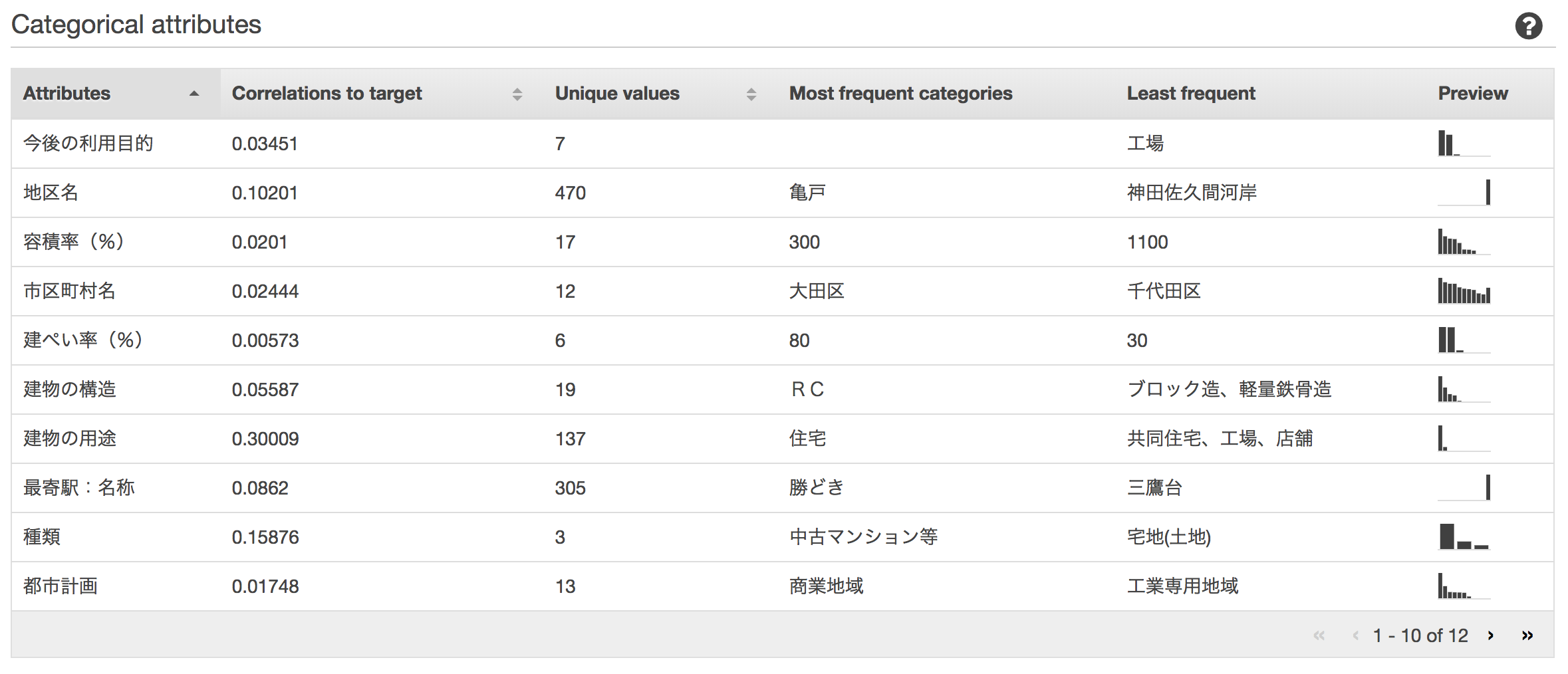
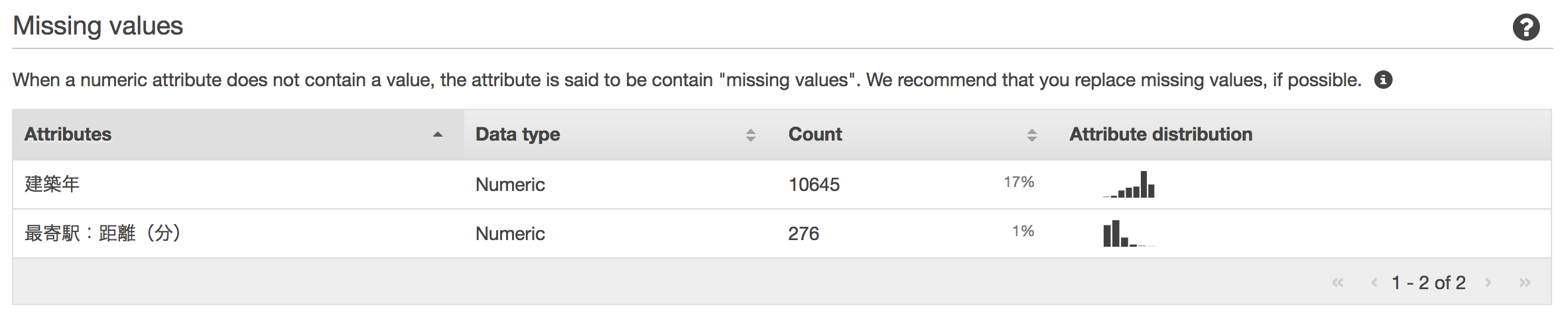
その他にも、Amazon MLにデータを登録するだけで、欠けている値、カラムごとの分布図などの統計情報、ターゲットとの相関の強さなどを確認することができます。
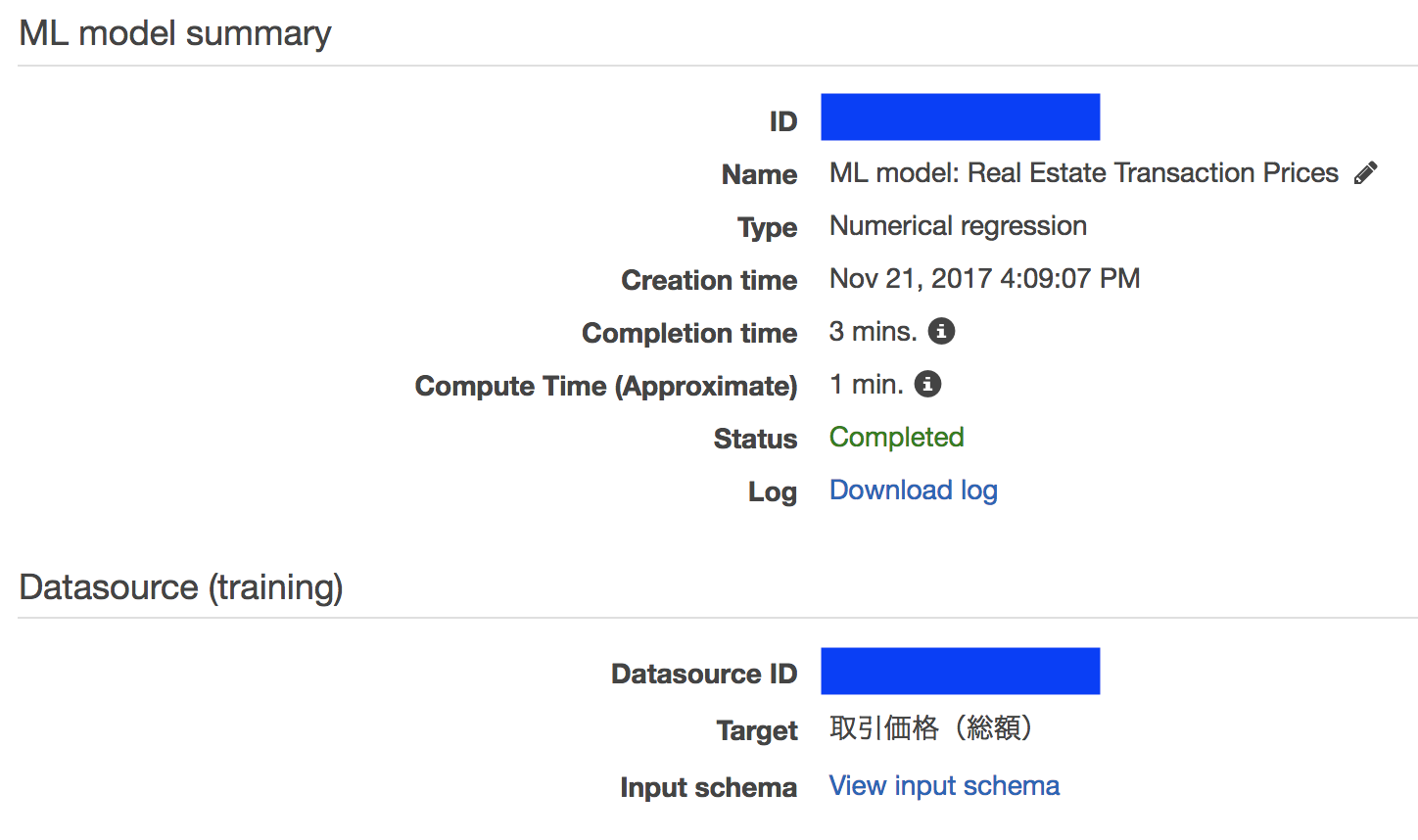
先程作成したデータソースを入力データとして、機械学習モデルを作成します。
ターゲットの型によってAmazon MLが自動的に学習アルゴリズムを決定するのですが、今回は取引価格(総額)=数値をターゲットとするので、回帰分析が使用されていることが確認できます。
また、デフォルトで作成されたレシピは以下のようになりました。
{
"groups": {
"NUMERIC_VARS_QB_500": "group('建築年','最寄駅:距離(分)','面積(㎡)','取引時点')"
},
"assignments": {},
"outputs": [
"ALL_CATEGORICAL",
"quantile_bin(NUMERIC_VARS_QB_500,500)"
]
}評価が完了したら確認してゆきます。回帰分析の場合、RMSE(二乗平均平方根誤差)が評価の基準となっています。

RMSE baselineは「常にターゲットの平均値を予測の回答とする架空の回帰モデルのRMSE」となっており、このベースラインを基準に、機械学習モデルとしての精度を判断することができます。
この結果を見ると、ベースラインよりは精度が高いモデルを作成できていますが、誤差もそんなに変わらないので、あまりいいモデルとはいえない気がします。また、平均取引価格が82,335,616円と、大きな値をとることを考慮に入れても、誤差の絶対値が大きいように見えます。
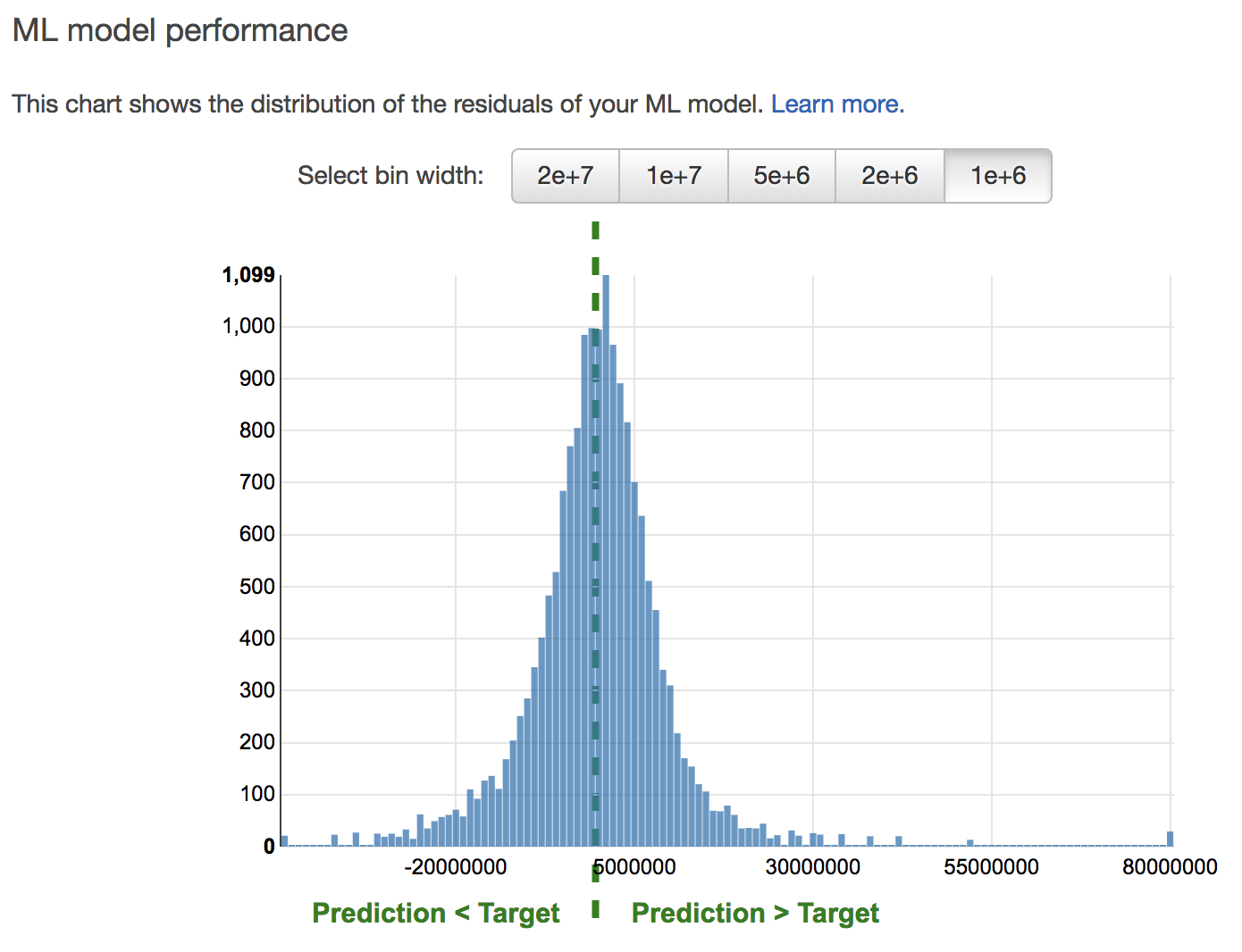
誤差のばらつきを確認することもできます。
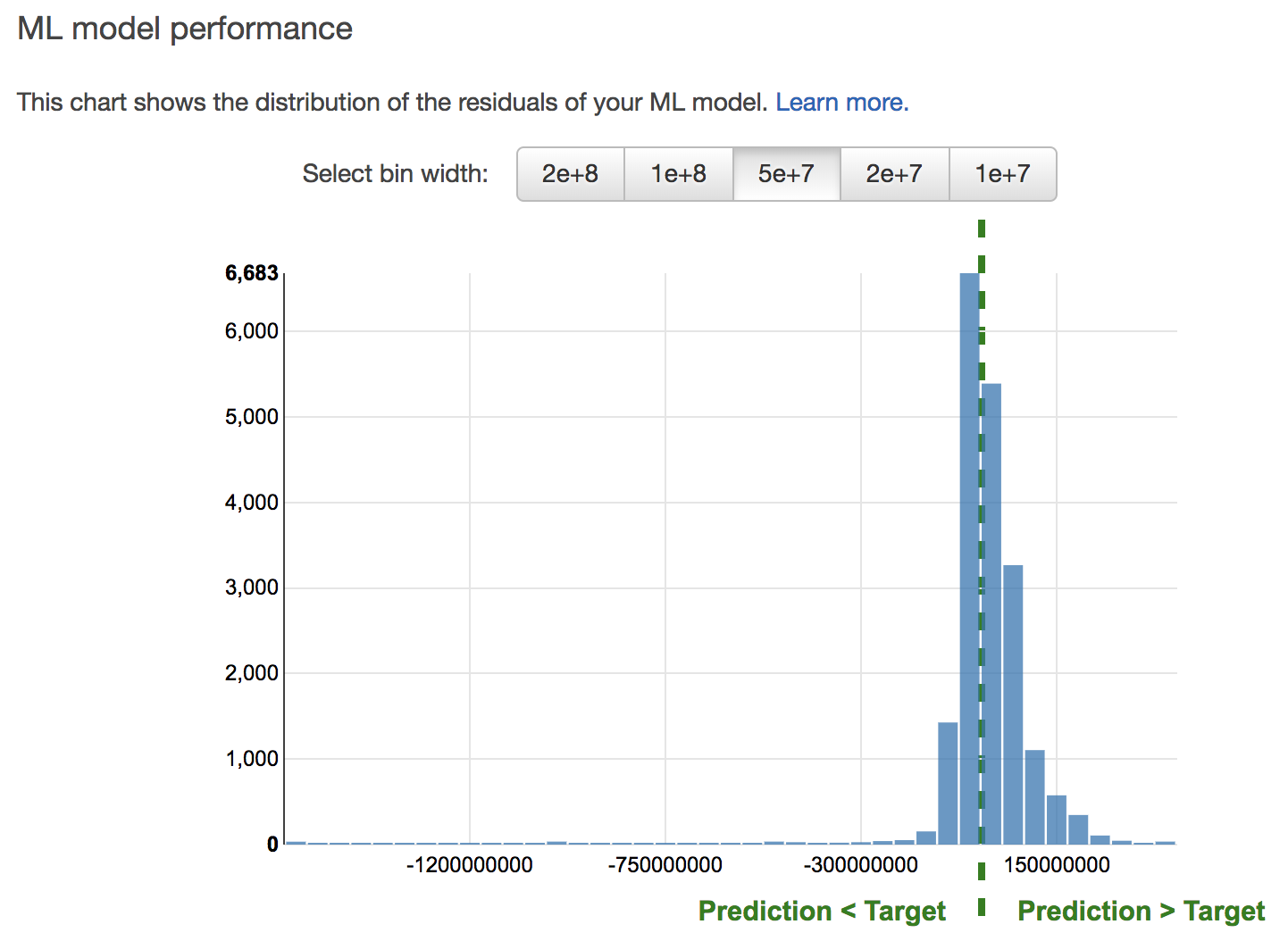
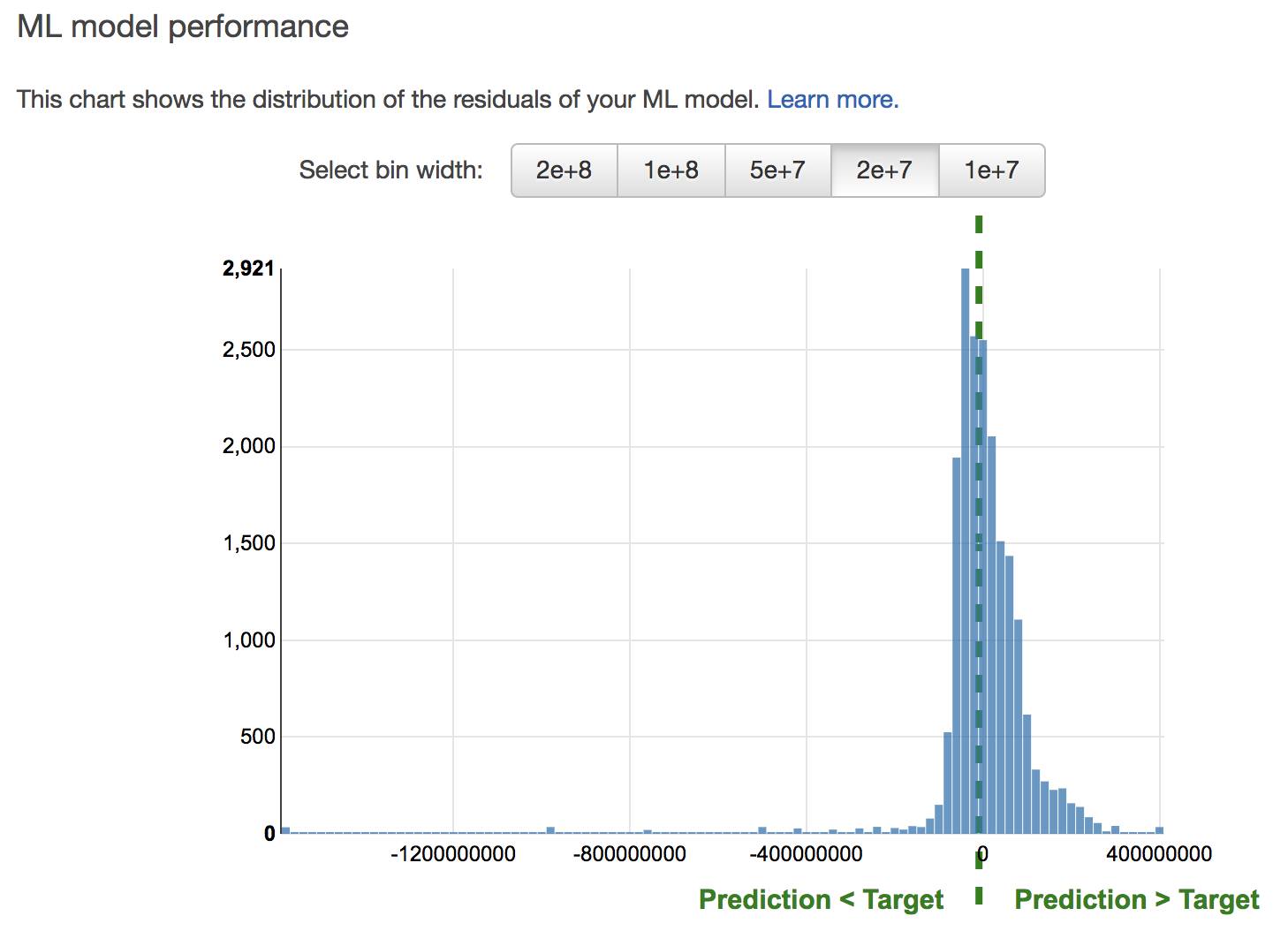
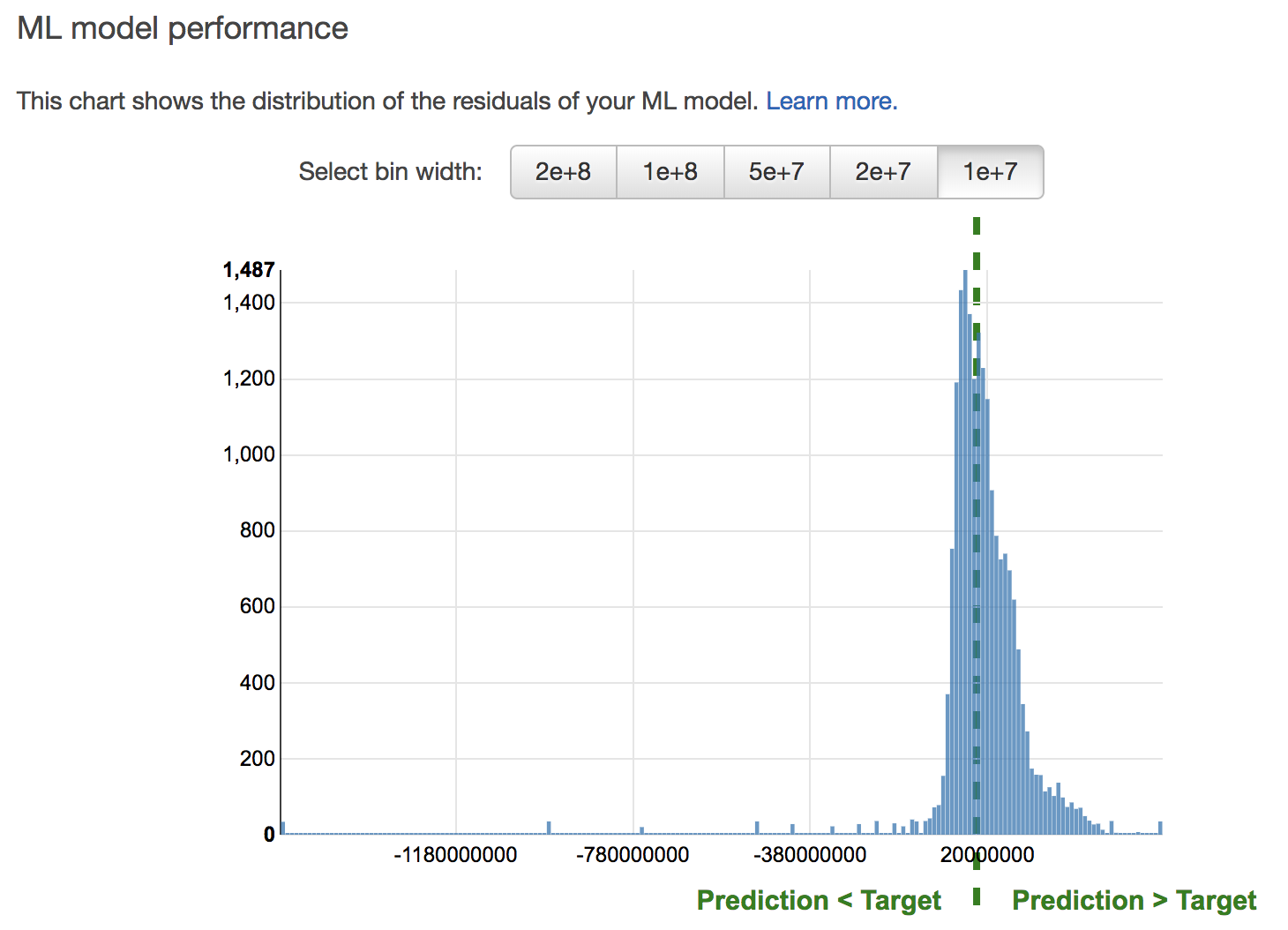
縦軸がデータの数、横軸が実際の値と予測値の誤差となっており、真ん中の緑の線のときが、誤差0で予測が的中した時となります。これをみると、このモデルでは、実際の値よりも高い値を予測してしまっているデータの方が多いとわかります。
傾向はなんとなくでていますが、精度はあまりよくないので、モデルをチューニングしてゆきます。
まず、ターゲットの分布を見ると、極端に数が少ないデータがあることがわかります。この図だと、100億円以上の物件は100レコードほどしかなく、アンバランスな分布になっていることがわかります。
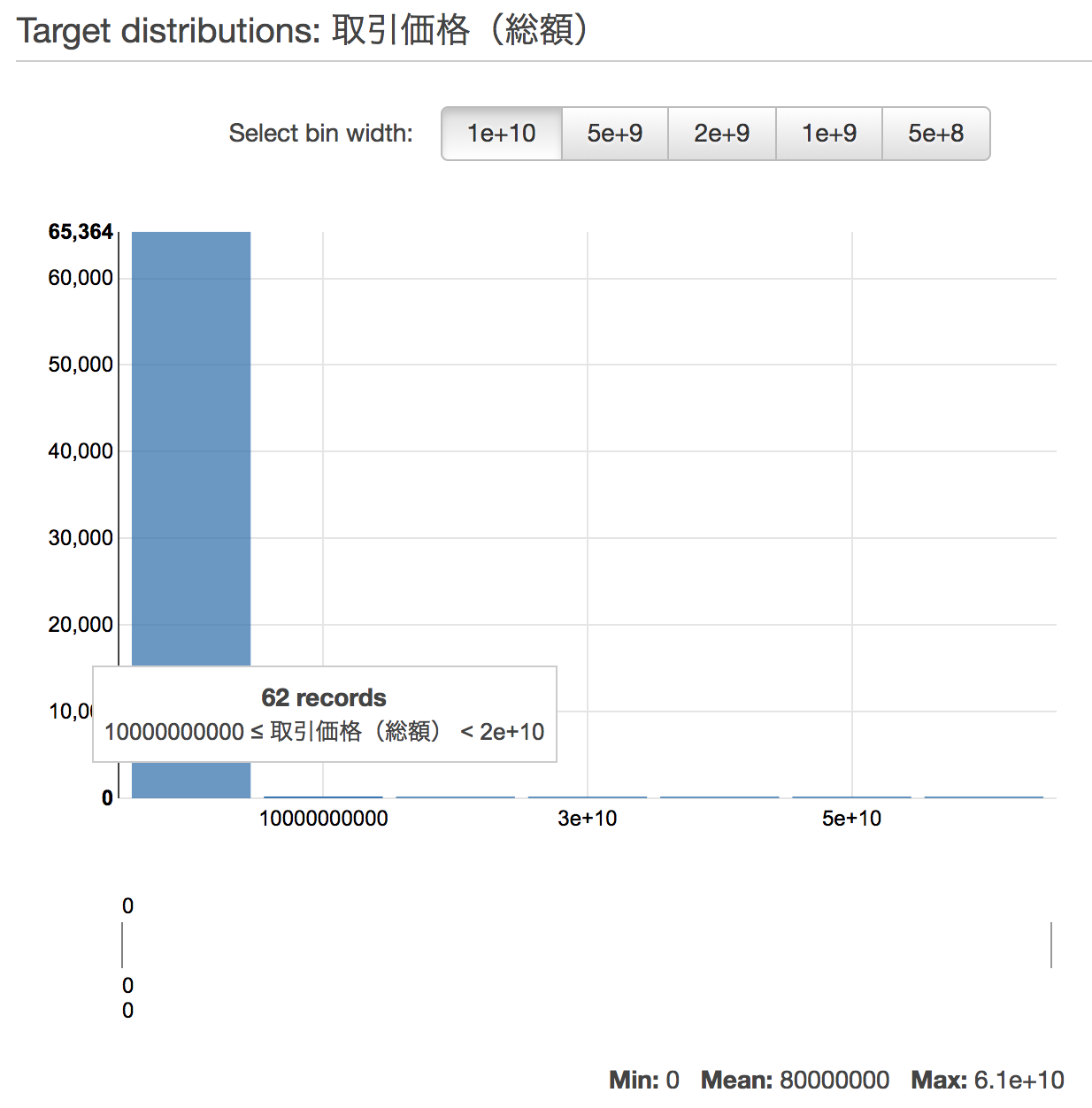
このような外れ値を除外することで精度をあげてゆきます。何度かデータを加工したあと、最終的に、以下のような分布になりました。
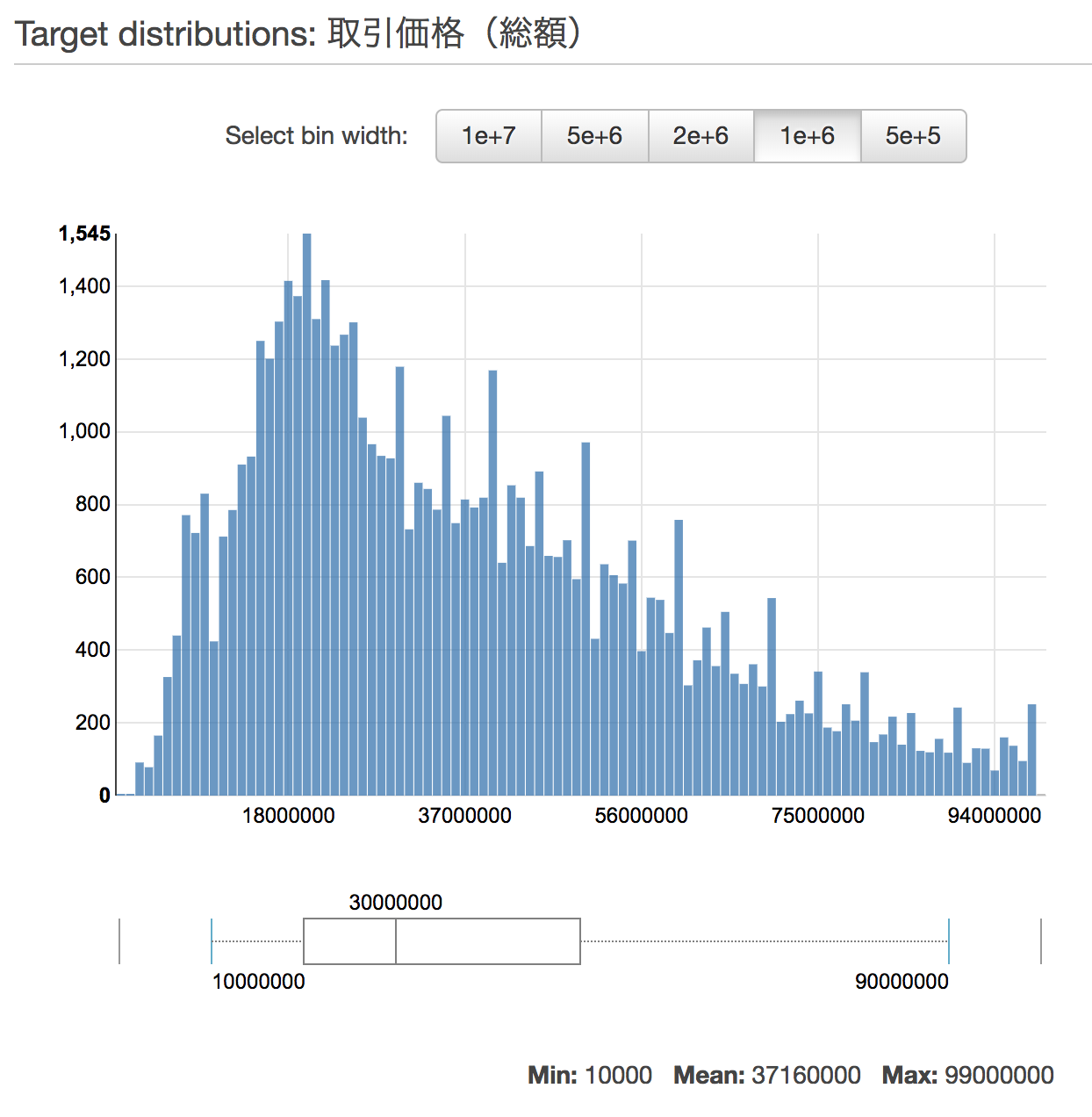
具体的には、取引価格1億円以上のデータを除外しています。この時点でのデータ件数は57,000件ほどとなりました。
Amazon Machine Learningでは、デフォルトで、入力データの最初の70%をトレーニング用データに使用し、残り30%を評価用データに使用します。今回用意したデータの順序はランダムではないので、モデル作成時にランダムでデータを選ぶようにしてあげます。

ここで最初のモデルのレシピを確認してみます
{
"groups": {
"NUMERIC_VARS_QB_500": "group('建築年','最寄駅:距離(分)','面積(㎡)','取引時点')"
},
"assignments": {},
"outputs": [
"ALL_CATEGORICAL",
"quantile_bin(NUMERIC_VARS_QB_500,500)"
]
}これをみると、数値型がすべて四分位ビニング変換されていることがわかります。これは、例えば、取引時点などは、2005年からの西暦をデータとして持っているだけで、細かいばらつきはないので、binの数が500が正しいとは思えません。そこで今回のデータでは、いくつかデータ型を修正し、数値型のカラムは以下に、他のカラムはカテゴリー型にしました。
レシピはこちらのようになります。
{
"groups" : {
"NUMERIC_VARS_QB_500" : "group('建築年','面積(㎡)')"
},
"assignments" : { },
"outputs" : [ "ALL_CATEGORICAL", "quantile_bin(NUMERIC_VARS_QB_500,500)" ]
}上記を行なった結果、最終的な評価は以下のようになりました。

476,966,249だったRMSEは、9,636,617となり、最初と比べると大幅に精度を改善したことがわかります。ベースラインRMSEと比べると、約55%誤差を削ることができました。取引価格は平均値が37,163,239円と大きな値をとるデータなので、一旦機械学習モデルとしては成立するのではないでしょうか。
その他にも、チューニング方法として、パラメーターの正規化、デカルト積の追加など、Amazon ML側でレシピが用意されています。
例えば、すべての数値を正規化したい場合は、以下のようなレシピを書くことができます。
{
"groups" : { },
"assignments" : { },
"outputs" : [ "ALL_CATEGORICAL", "normalize(ALL_NUMERIC)" ]
}本来、正規化をするには、プログラムを書いた上でクレンジングを実行する必要がありますが、Amazon MLではこのように書くだけであとはいい感じにやってくれます。面倒な作業をする必要がなくなりますし、バグを埋め込むリスクも減らすことができます。
同じように、デカルト積を使って、変数同士の相互作用を確かめるパラメーターを追加することもできます。
例えば、収入を予測するモデルを作成したいとします。パラメーターに職業と大学がある場合、それぞれ個別での影響に加えて、職業+大学と組み合わせたときの影響を考慮するパラメーターを解析に追加することができます。
{
"groups" : { },
"assignments" : { },
"outputs" : [ "ALL_CATEGORICAL", "cartesian('職業','大学')" ]
}このように、自作データクレンジングのコストやリスクをAmazon Machine Learning側で吸収することができます。他にもいろいろな調整ができるので、詳しくはドキュメントを参考にしてみてください。
Amazon Machine Learningでは、特定のデータに対して、同期的な予測(リアルタイム予測)をすることができます。
例えば、以下の千代田区のデータ(Aとする)を元に予測をしてみます。
種類|都道府県名|市区町村名|地区名|最寄駅:名称|最寄駅:距離(分)| **取引価格(総額)** |間取り|面積(㎡)|建築年|建物の構造|建物の用途|今後の利用目的|都市計画|建ぺい率(%)|容積率(%)|取引時点
--|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|--
中古マンション等|東京都|千代田区|飯田橋|飯田橋|1|51000000|2LDK|55|昭和59年|SRC|住宅|住宅|商業地域|80|600|平成28年第3四半期該当モデルの、Try real-time predictionsでデータを入力します。
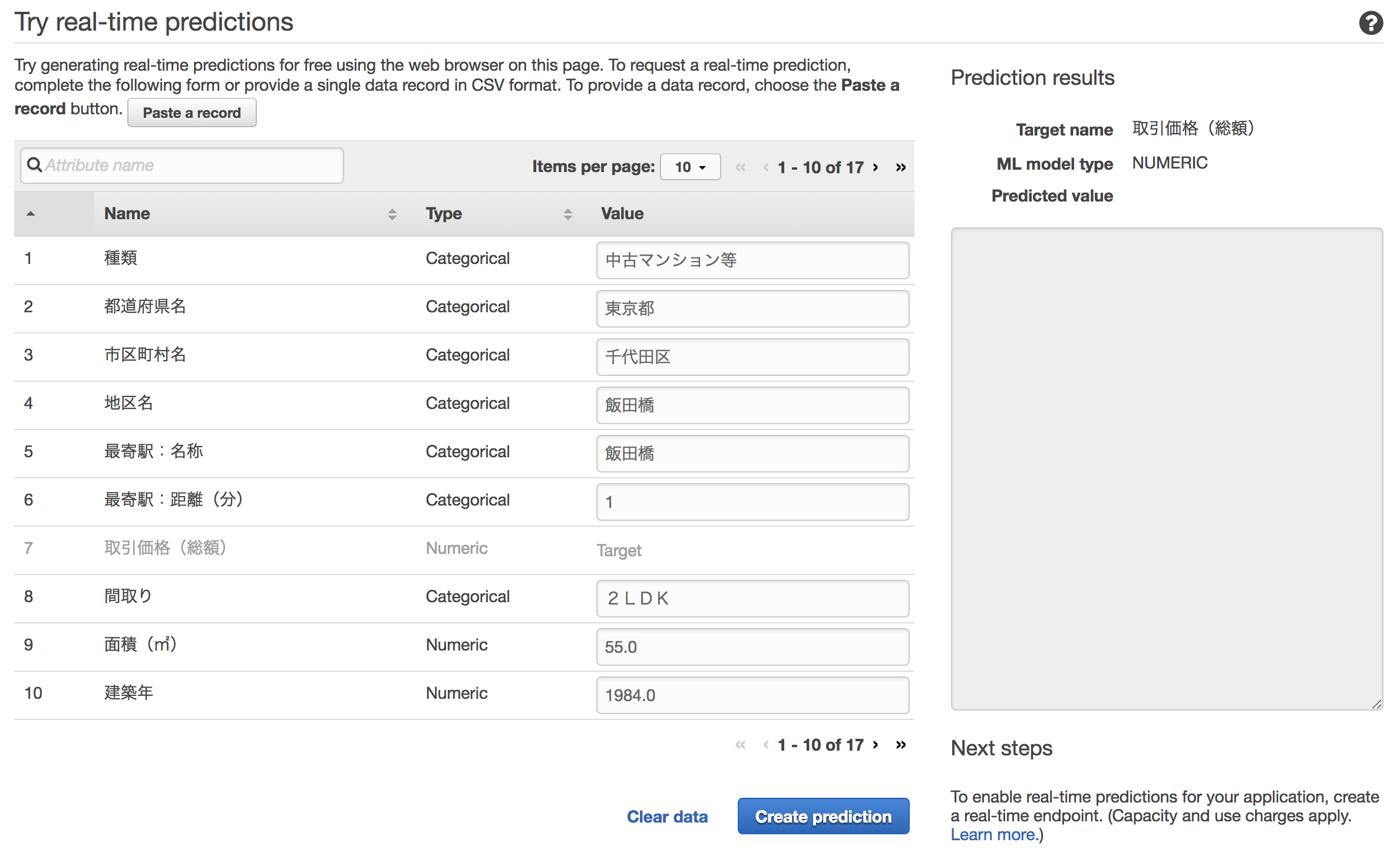
結果は以下のようになりました。

予測値が48,814,088円で、実際の値は51,000,000円だったので、誤差は約200万円となります。
次に、場所を変えて、大田区のデータ(Bとする)を元に予測をしてみます。
種類|都道府県名|市区町村名|地区名|最寄駅:名称|最寄駅:距離(分)| **取引価格(総額)** |間取り|面積(㎡)|建築年|建物の構造|建物の用途|今後の利用目的|都市計画|建ぺい率(%)|容積率(%)|取引時点
--|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|--
中古マンション等|東京都|大田区|大森北|平和島|5| **25000000** |1LDK|45|昭和59年|RC|住宅|住宅|商業地域|80|400|平成29年第1四半期結果は以下のようになりました。
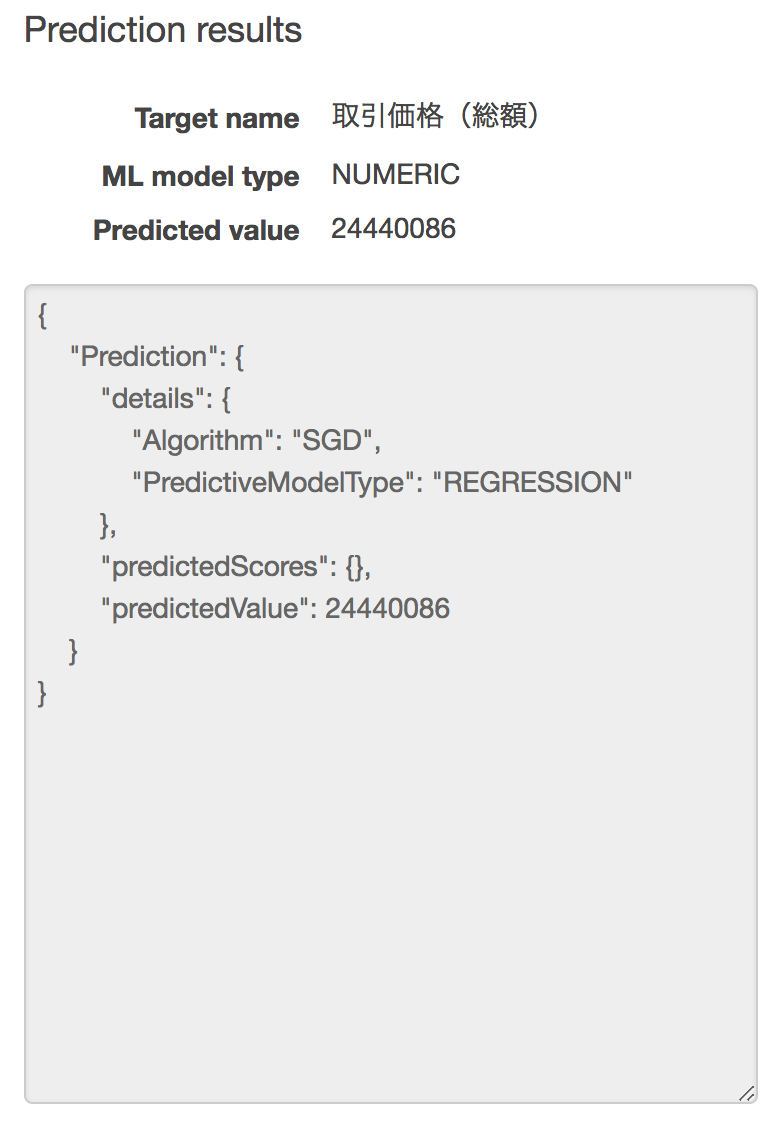
予測値が24,440,086円で、実際の値は25,000,000円だったので、誤差は約50万円となります。A Bの結果をみると、そこそこの精度がでているように思えます。
では、最後に、以下の値段が高めのデータ(Cとする)を元に予測をしてみます。
種類|都道府県名|市区町村名|地区名|最寄駅:名称|最寄駅:距離(分)| **取引価格(総額)** |間取り|面積(㎡)|建築年|建物の構造|建物の用途|今後の利用目的|都市計画|建ぺい率(%)|容積率(%)|取引時点
--|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|--
中古マンション等|東京都|千代田区|飯田橋|飯田橋|4| **99000000** |3LDK|70|平成19年|RC|住宅|住宅|商業地域|80|500|平成28年第1四半期結果は以下のようになりました。
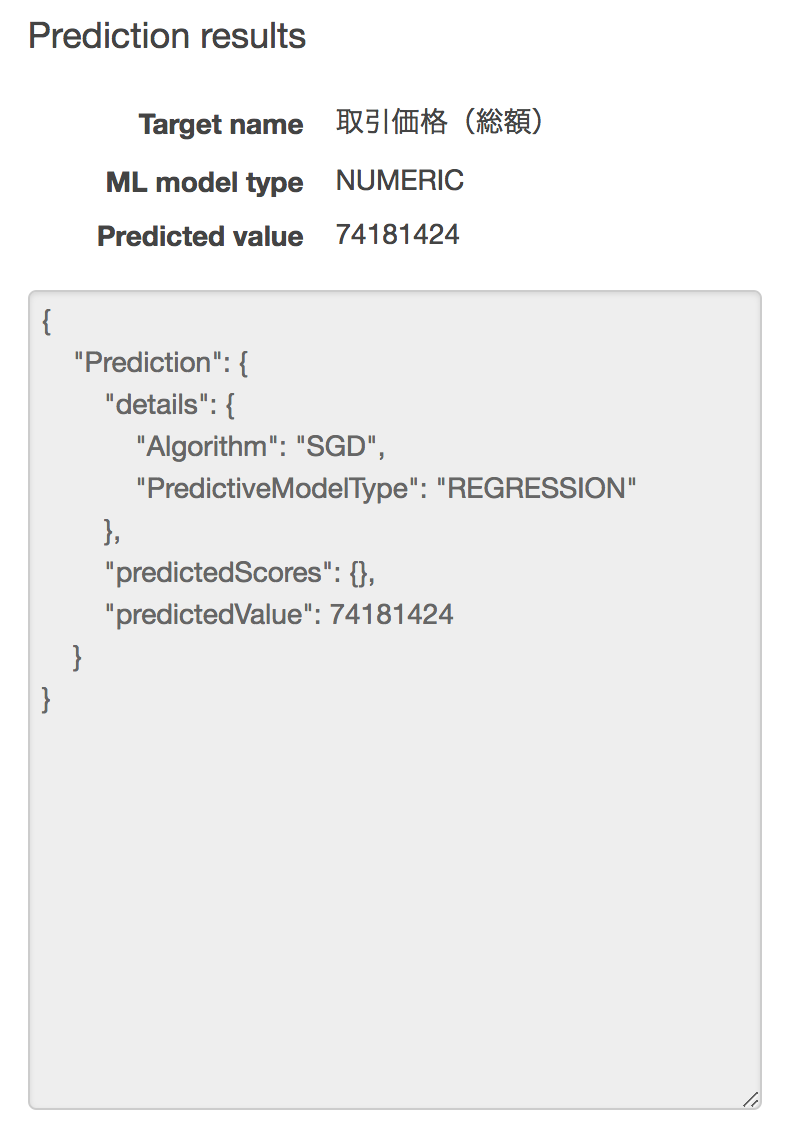
予測値が74,181,424円で、実際の値は99,000,000円だったので、誤差は約2400万円となりました。A Bと比べると誤差が大きいように見えます。ここで今一度、データの分布に戻ってみると、
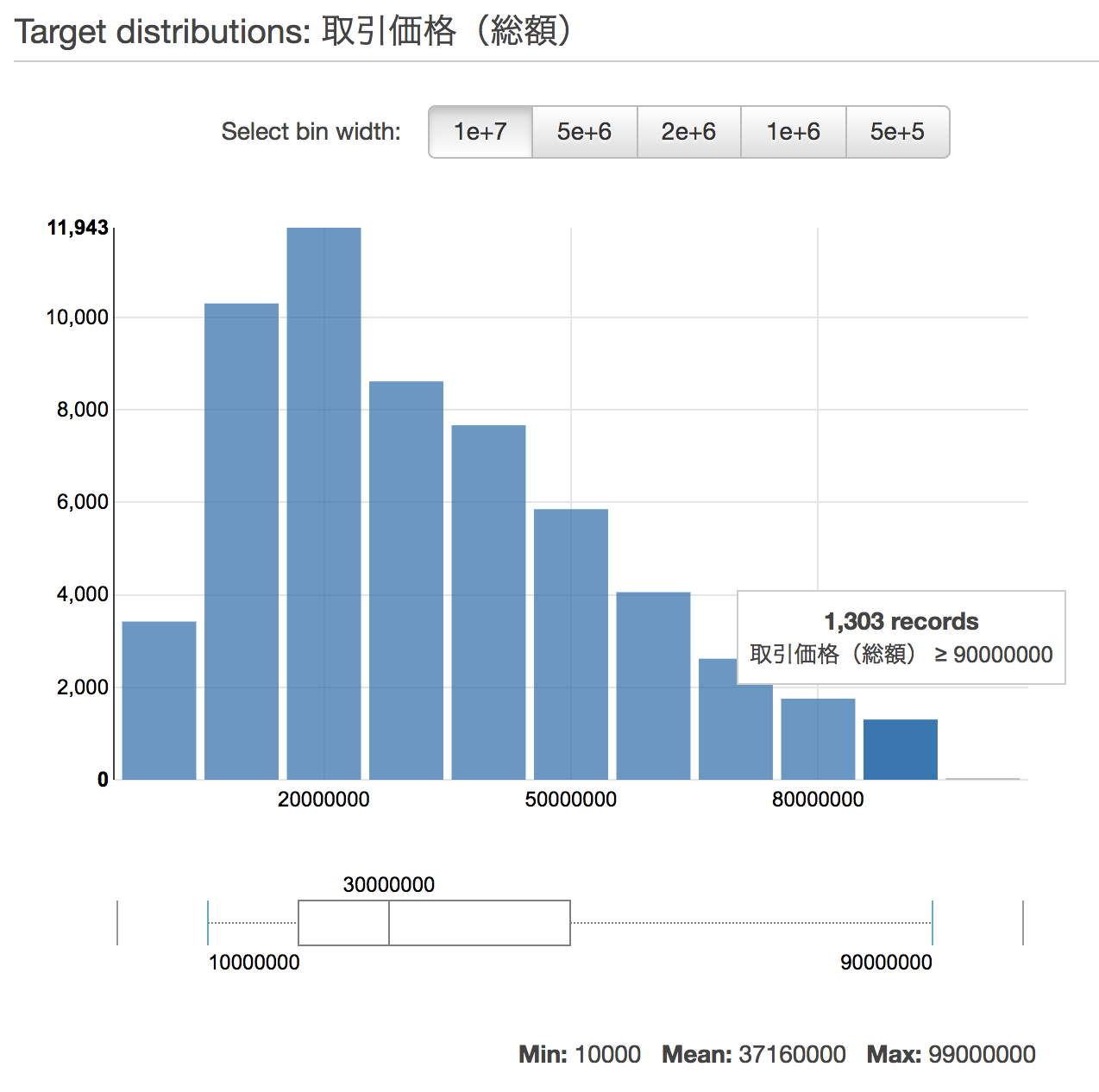
Cのデータは、取引価格9900万円なので、この分布でいうと最もデータの少ない範囲にあるということがわかります。そのため、学習するデータが少なく、誤差も生まれやすいと考えられます。ただし、分布が少ないデータでも、全体としてモデルの精度向上に影響を及ぼしている場合もあるので、一概にはいえません。
このように、作成したモデルが得意とする予測しやすいデータ、しにくいデータはありますが、専門的な知識を必要とせずに、そこそこ精度のある機械学習モデルを作成することができます。
このリアルタイム予測を、API Gatewayなどのエンドポイントと組み合わせれば、独自の価格予測APIを作成することも可能です。また、多数の観測値をあわせて予測する、非同期なバッチ予測をすることもできます。
今回はAmazon Machine Learningを実際に使いながら、その機能を紹介させていただきました。
このように、機械学習に関してほぼ素人な私でも、素早く、それなりの結果を出すことができました。より凝ったことをしようとすると知識が必然となってきますが、本来時間がかかる部分をAmazon Machine Learningで自動化することができるので、本格的な機械学習に際しても、その導入の支援をすることができます。
また、データサイエンティストへの採用と投資にコストをかけることなく、そこそこ精度のある機械学習をビジネスに導入することもできます。(※もちろん独自のカスタマイズが難しいことや、データ解析が一部ブラックボックス化するというデメリットはあります)。
re:InventでAmazon SageMakerも発表されましたが、機械学習にかかるコストを自動化してゆけるのは、ビジネスサイドにとっても、データサイエンティストや機械学習エンジニアにとっても嬉しいのではないでしょうか。
弊社ではAWSを使用した機械学習の導入支援も行っておりますので、ぜひお気軽にお問い合わせください。