株式会社MMMが2017年度下半期に注力している技術領域(サーバーレス、IoT/AI、クラウドセキュリティ)
kuni
デロイト トーマツ ウェブサービス株式会社(DWS)公式ブログ

こんにちは、ぬまです。
本稿では AWS ANGEL Dojoで開発したシステムの技術構成 に絞り、開発時の構成に沿ってアーキテクチャと技術選定の意図を整理します。(忘れないうちにまとめたいとは思っていたものの、ブログにするのが遅くなってしまいました・・・)
前提として Lambda や API Gateway の用語説明は最小限にし、技術選定理由を中心に書きます。
気になったセクションだけでも読んでいただけると幸いです。
ANGEL Dojo 2025 の概要や参加の動機、サービス「AI審査アシスタント mody」の全体像については、別記事 AWS ANGELDojo2025で最優秀技術賞を獲得しました! に投稿していますので、合わせてお読みいただけると嬉しいです。

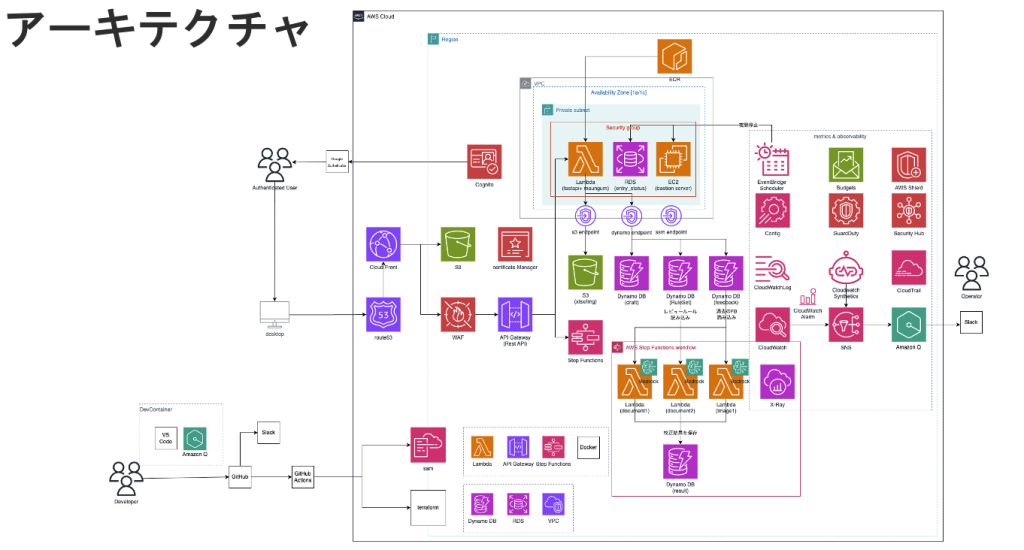
図の各ブロックに対応する形で、利用者リクエストから審査ワークフローまでを簡単に解説します。
React アプリは Terraform で用意した S3 と CloudFront に載せ、Cognito で認証します。本番のビルド時には API Gateway のベース URL(FastAPI 用と審査実行用)を環境変数として注入するため、インフラの出力とフロントのビルドが連鎖する前提になっています。
業務 API は 1 つの Lambda 上の FastAPI(後述の Lambdalith)に集約し、審査パイプラインの開始だけは別の API Gateway リソースから Step Functions の StartExecution に直接つないで非同期化しています。審査は長時間になりやすく処理時間が読めなかったので、HTTP の同期レスポンスとワークフローの寿命を切り離す意図です。
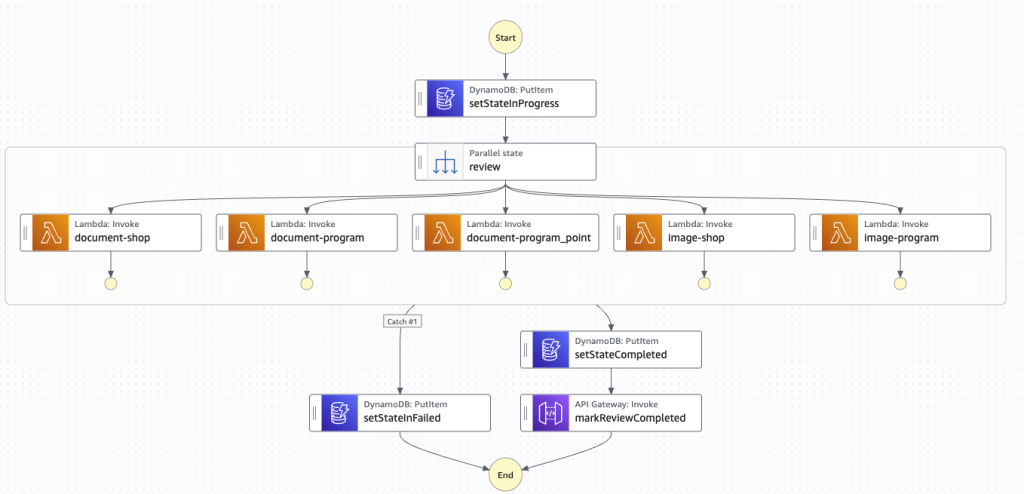
ステートマシンが、文書・画像レビュー用の コンテナ型 Lambda を並列実行します。開始時に DynamoDB の審査ステータスへ 進行中 などの状態を書き込み、各 Lambda 内で Bedrock を呼び出して結果を DynamoDB に蓄積する流れです。X-Ray トレースや Step Functions のログ設定も SAM 側で有効にしており、分散した処理の追跡を意識した構成にしています。
入稿データやルール・審査結果の多くは キー・バリュー中心でスループットを上げる用途として DynamoDB に構築しています。
一方、アプリのダッシュボードに表示する情報(一覧・絞り込み・担当者・チケットステータス・レビュー完了の有無など)は、想定される クエリパターンが多様になりやすいため、RDS(MySQL)側で管理しています。担当者アサインやレビュー完了フラグなどを SQL とインデックスで柔軟にクエリする前提で、ダッシュボード専用の行をリレーショナルに持ちます。「全部 NoSQL」でも実装は可能ですが、ダッシュボード要件の変化に GSI を増やし続けるより、チームが慣れた SQL と Alembic で進めやすいと判断しました。
ここからは採用したコンポーネントごとに、選定理由を整理します。
うまくいった点
負担やリスク(二系統の突き合わせ)
REST エンドポイントを FastAPI アプリ=Lambda(コンテナイメージ) にまとめる Lambdalith 方式を採用しました。関数をエンドポイントごとに分割する方式と比べ、ルーティングとミドルウェアをアプリ内で完結させられます。
Lambdalith 方式のメリット
ただし Lambda を VPC 内に置くと設計が一気に複雑化する、という論点があり、ANGEL Dojo ではここはしっかりと議論しました。
VPC 内 Lambda が複雑になる理由
今回の構成では Cognito を使ったアプリケーション側の処理も Lambda で実装していましたが、当時はCognito 用の VPC エンドポイントは存在しません(現在はCognito用のVPCエンドポイントは存在しています。https://aws.amazon.com/jp/about-aws/whats-new/2025/11/amazon-cognito-user-pools-private-connectivity-aws-privatelink/)。
そのため「VPC 内 Lambdalith 1 本だけ」にすると、Cognito など VPC 外でよいはずの処理のために NAT ゲートウェイを立てるかという議論に落ちます。コストの観点から、不要な NAT だけを増やしたくない、という判断になりました。
結果としての構成
の 2 本に分けました。SAM では VPC 内用のメイン API 用 LambdaとVPC 外用の補助 API 用 Lambdaとして、別リソースに定義しています。コードベースは FastAPI のままですが、デプロイ単位として FastAPI で実装された Lambda が二つあるイメージです。
2 本のLambdalith(VPC 内/外)に分けて得たこと
運用で増えること
採用効果
/docs など)をそのままフロントへの仕様のたたき台にできました。ANGEL Dojo期間でも「口頭のすれ違い」を減らす効果は大きかったです。バックエンド用 DevContainer は 開発用 Docker Compose と結合し、Terraform / AWS CLI / Session Manager など 本番に近いツールチェーンをコンテナに閉じ込めています。
ANGEL Dojo のチームは 経験年数や得意領域がそろわない編成であり、初学者の方にも参加いただく前提でした。各人の PC に Python/Node/Terraform のバージョンをそろえて入れる、という 個別の初期セットアップに時間を取られないことが重要だと考え、DevContainer を軸にしました。リポジトリを開き、コンテナを起動できれば 短時間で開発のスタートラインに立てられる状態を目指し、結果として 全員が環境構築ではなく本来の機能開発に集中できるようにしています。
チーム全体の開発速度
CI/デプロイのオーバーヘッド
sam build --use-container のように ビルドをコンテナ内で行う場合も、Docker レイヤーやパッケージキャッシュの設計を誤ると毎回フルビルドに近くなり、同様に時間がかかりやすいです。API 層と審査ワークフローの両方で Powertools for AWS Lambda の Logger を使い、JSON ログとサービス名などの共通属性を揃えています。SAM の全体設定でログ形式を JSON にそろえ、CloudWatch Logs Insights で横断しやすくする意図です。
揃えた効果
運用ルール
Terraform で VPC・RDS・DynamoDB・Cognito・S3・踏み台など ライフサイクルが長く、チームのインフラ定番になりやすいリソースを管理し、SAM で API Gateway・Lambda・Step Functions など アプリリリースの頻度が高いサーバレスを管理しています。
手元のタスク実行(例: SAM のビルド/デプロイ)や GitHub Actions のインフラ系ワークフローでは、Terraform の出力を SAM のパラメータに渡して スタック間の依存を明示的に解決しています。
ツール分担のメリット
sam build とコンテナイメージの相性も活かしやすいです。2スタックの注意点
terraform apply のあと sam deploy を固定順で流すことで緩和しています。Strands Agents SDK(PyPI では strands-agents など)は、Python で エージェント型の生成 AI アプリを組み立てるためのオープンソースのフレームワークです。Agent にモデルとシステムプロンプトを渡し、ユーザ入力相当の文字列を渡して実行する、というシンプルな入り口が用意されています。
モデル提供者として Amazon Bedrock を使う場合は strands.models の BedrockModel を指定し、bedrock-runtime 経由で推論します。AWS の公式ドキュメントでは、Strands と Amazon Bedrock AgentCore(メモリやランタイムデプロイなど)を組み合わせる例も載っており(Strands Agents SDK と AgentCore)、エージェント実装とセットで語られることが多いです。公式サイトのドキュメントは Strands Agents から辿れます。
補助的に strands-agents-tools のようなツールパッケージもあり、画像読み取りなど必要に応じてエージェントに能力を足せます。mody では画像レビュー用 Lambda に strands-agents と strands-agents-tools を入れて画像への審査を実現しています。
ここでいう「直接」は、boto3 の bedrock-runtime クライアントに対し、converse や invoke_model などを 自前で組み立てるやり方のことです。
| 観点 | Bedrock API 直接 | Strands(Agent + BedrockModel) |
|---|---|---|
| ボイラープレート | メッセージ配列、システムプロンプト、推論パラメータを API 都度・モデル都度で組み立てる必要がある | モデル ID・リージョン・温度・タイムアウトなどを BedrockModel に集約し、呼び出し側はプロンプト文字列に寄せられる |
| API の変化への追従 | Bedrock のリクエスト/レスポンス形式の差分をアプリコードがすべて吸収する | 提供者実装側(SDK)のアップデートに一部委ねられます。アプリはエージェントのインタフェースに留めやすい |
| エージェント機能の拡張 | ツール呼び出しやマルチターンを自前でループと状態管理として実装する必要がある | Agent とツール定義の組み合わせで、後から画像ツールや追加ステップを足しやすい |
| 依存と制御 | 依存は boto3 のみに抑えやすく、細部まで制御したい場合向け | フレームワーク分の依存と学習コストが増える。挙動のデバッグは SDK 内部も意識する必要がある |
ANGEL Dojo での開発において、Strands が優れている点は次のような観点です。
Agent に集約されます。converse の生 JSON をいじり続けるより、エージェント層に載せた方が変更点が追いやすい。一方で、レイテンシの最小化やバイナリプロトコルの完全制御が最優先なら、直接 API の方がシンプルなこともあります。また Strands は抽象化の分、不具合やバージョンアップ時には SDK 側の挙動も確認対象になります。
ANGEL Dojo では、短期間でチームが同じパターンで Bedrock を触り、あとから審査要件が増えても エージェント周りに変更を閉じやすいことを優先し、Strands を選びました。
文書・画像の審査ロジックでは Agent と BedrockModel を使い、プロンプト実行とモデル設定(リージョン、タイムアウト、温度など)を エージェント層に閉じる形にしています。レスポンスは JSON 抽出に失敗した場合のフォールバックもコード側で持ち、生成物のブレを運用で許容できるラインに収める工夫をしています。
実装で揃えられたこと
生成まわりのメンテ
ここでいう AI オンボーディングは、「とりあえず Q にコードを書かせる」ことではなく、プロジェクト固有の前提をドキュメントとルールで先に渡し、Q の振る舞いを開発フローに乗せることを指します。一般的な言語知識やフレームワークの定石は LLM 側にありますが、リポジトリ構成・仕様・コーディング規約や開発ルールは学習データにないので、AmazonQ.md・README.md・.amazonq/rules/*.md などで明示的に与える、という整理です。
「テスト仕様書(開発者)→ テストコード生成と整形・実行(Amazon Q)→ 結果のサマリ(Amazon Q)」 という一連の流れに沿った運用です。ざっくり次のとおりです。
docs/job_test/ 配下などに、ジョブ(または対象モジュール)ごとの Markdown で 単体テスト仕様を書きます。テスト ID・観点・入力データ・期待結果を表形式でそろえ、どの入力に対してどういう出力(または失敗)を期待するかが一目で追えるようにし、Amazon Q がそのままテストコードを作成できる粒度にします。AmazonQ.md)AmazonQ.md に書き、Amazon Q が自動で読み込む前提にしました。CI でテストを必須ゲートにしていたわけではありませんが、開発者が期待値を仕様書に書き、Amazon Q はその記述と Pytest の結果だけを手がかりにするという分担にすることで、単体テスト追加のスピードと、チーム内での説明可能性の両方を実現しています。期待値の最終判断は常に開発者側(仕様書の記述)に置く、という前提は変わりません。
本番に近い構成でスループットとエラー率を見るため、Distributed Load Testing on AWS を用いて API とワークフロー周りの余裕を確認しました(閾値や数値は環境ごとに異なるため、ここでは割愛)。サーバレスはスケールしやすい一方、同時実行数・レート制限・下流の Bedrock がボトルネックになりうるため、そこを意識したシナリオ設計が重要でした。
以上が mody のアーキテクチャと主要な技術選定の整理です。ANGEL Dojo の短期間でも「自分たちが説明できる構成」に寄せることを意識し、チーム全員で。
さまざまな角度から技術的な説明をしました。読み手によって関心が分かれると思いますが、どれか一つのセクションでも有意義な情報になりますと幸いです。