【マルチクラウド】AWS⇔Azureでデータベース連携して実現する超高可用性【Azure × AWS】
oyuchan
デロイト トーマツ ウェブサービス株式会社(DWS)公式ブログ

おはようございます!DWSのkimです!
今回Athenaを使って、GuardDutyのログ分析をしてみたので、その方法について紹介します!
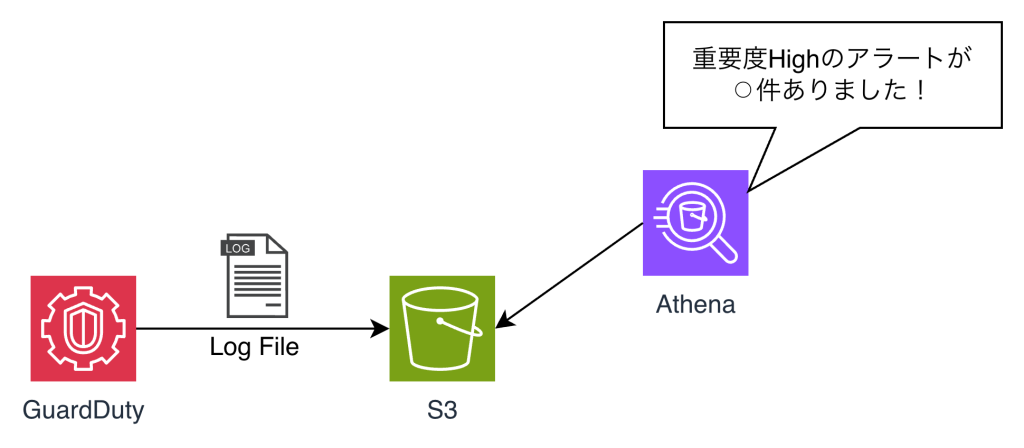
今回はS3に溜まったGuardDutyのログを、Athenaで分析し、Highのアラートが何件あったか確認できるようにしたいと思います。
作成するバケットは下記の2つ必要になります。
作成方法は下記AWS公式ページを参考にしてください。
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/userguide/create-bucket-overview.html
GuardDutyのログをS3に格納するときにKMSを使用しないといけません。
作成方法は下記AWS公式ページを参考にしてください。設定は一旦全てデフォルトでOKです!項番1-3で修正しますので!
https://docs.aws.amazon.com/ja_jp/kms/latest/developerguide/create-symmetric-cmk.html
作成方法は下記AWS公式ページを参考にしてください。
この時にS3のバケットポリシーと、KMSのキーポリシーを修正します。
生成された GuardDuty の検出結果を Amazon S3 バケットにエクスポートする
https://docs.aws.amazon.com/ja_jp/guardduty/latest/ug/guardduty_exportfindings.html
以下のURLから Athena コンソールを開きます。
https://ap-northeast-1.console.aws.amazon.com/athena

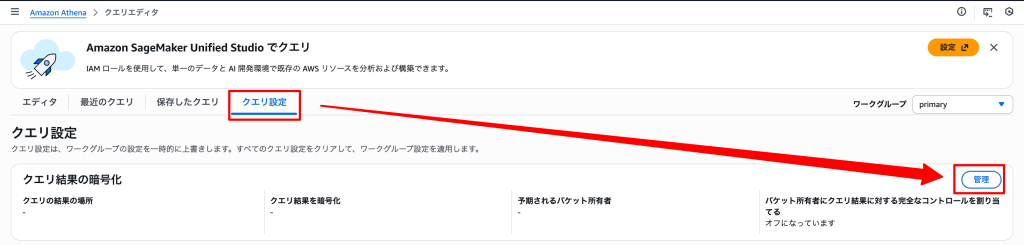
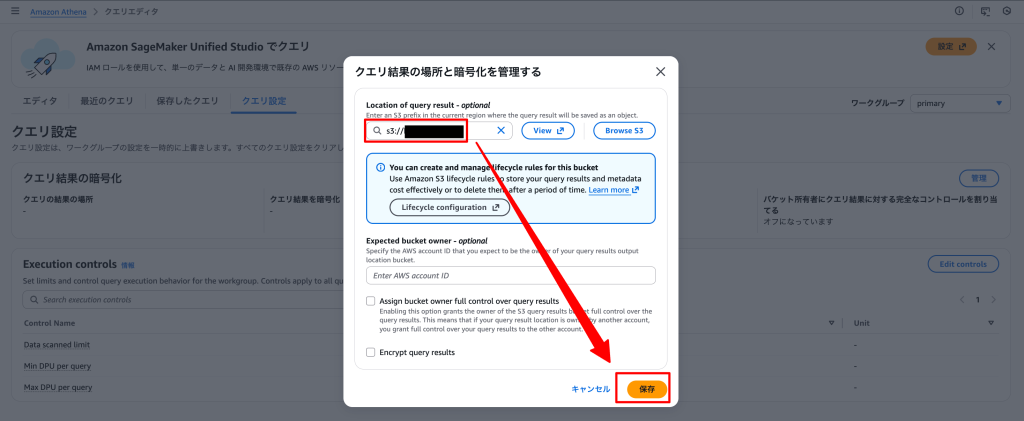
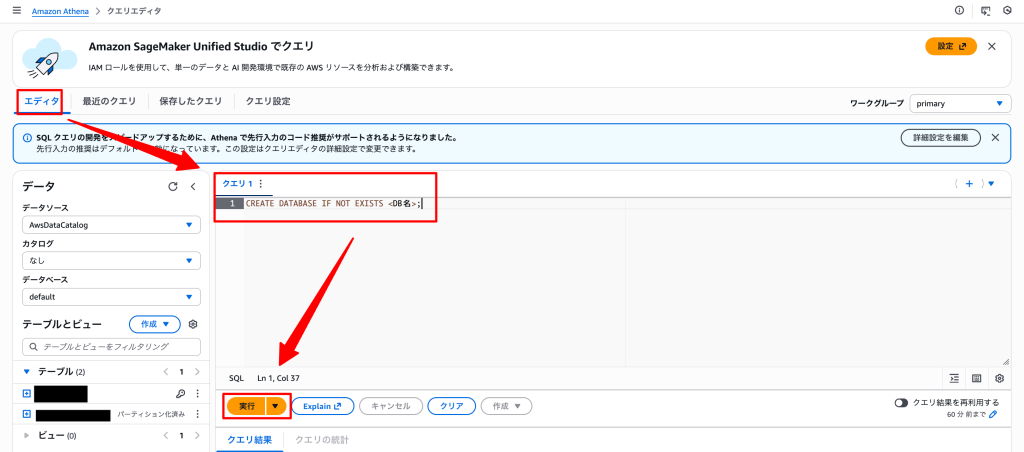
以下クエリを実行してください。
CREATE DATABASE IF NOT EXISTS <任意のDB名>;※<任意のDB名>に値を入力してから、実行してください
※クエリの実行場所は下記画像を参照してください(次項以降は画像を省略します)
以下クエリを実行して、Athenaのテーブルを作成してください。後ほどコードの詳細について解説させていただきます。
CREATE EXTERNAL TABLE IF NOT EXISTS <任意のDB名>.<任意のTable名> (
schemaversion string,
accountid string,
region string,
id string,
arn string,
type string,
resource string,
service string,
severity string,
createdat string,
updatedat string,
title string,
description string
)
PARTITIONED BY (
day string
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 's3://<バケット名>/AWSLogs/<アカウントID>/GuardDuty/<リージョン>/'
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.day.type' = 'date',
'projection.day.format' = 'yyyy/MM/dd',
'projection.day.range' = '2025/01/01,NOW',
'projection.day.interval' = '1',
'projection.day.interval.unit' = 'DAYS',
'storage.location.template' =
's3://<バケット名>/AWSLogs/<アカウントID>/GuardDuty/<リージョン>/${day}/'
);※上記<任意のDB名>、<任意のTable名>は修正して実行してください
※上記<バケット名>、<アカウントID>、<リージョン>は修正して実行してください
CREATE EXTERNAL TABLE IF NOT EXISTS <任意のDB名>.<任意のTable名> (
schemaversion string,
accountid string,
-- (省略)
description string
)<任意のDB名>の中に<任意のTable名>を作成するといったクエリになります。
また、schemaversion stringやaccountid string等はGuardDutyからS3に出力されるJSON 形式の検出結果になります。どんな項目があるかは、AWS公式ページに記載がありますので、下記をご参照ください。
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/querying-guardduty.html
PARTITIONED BY (
day string
)パーティションとはデータを「日付」「年」「地域」などの値ごとに区切って整理したものになります。
今回は下記S3の日付に関するオブジェクト部分をdayとして区切るつもりで、パーティションを設定します。

この後説明するTBLPROPERTIESのところで「パーティションのdayってS3の/2025/12/26の部分のことだよ〜」っていう設定を行います。
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'JSON データを読み込むためライブラリ(JSON SerDe ライブラリ)を指定している部分になります。AthenaはJSON の文字列をそのままだと読み取れないので、SQLのカラムに変換する仕組みが必要になります。
他にもAthenaではCSVやApache Parquetなどを変換することができます。詳しくは下記AWS公式ページをご参照ください。
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/supported-serdes.html?utm_source=chatgpt.com
LOCATION 's3://<バケット名>/AWSLogs/<アカウントID>/GuardDuty/<リージョン>/'Athenaが実際に読み込むデータが置いてある S3 のディレクトリを指定している部分です。
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.day.type' = 'date',
'projection.day.format' = 'yyyy/MM/dd',
'projection.day.range' = '2025/01/01,NOW',
'projection.day.interval' = '1',
'projection.day.interval.unit' = 'DAYS',
'storage.location.template' =
's3://<バケット名>/AWSLogs/<アカウントID>/GuardDuty/<リージョン>/${day}/'
);TBLPROPERTIESとはAthenaのテーブルに紐づく補助の設定項目(プロパティ)の集合です。今回だと「dayと言うパーティションはこういうルール(型、範囲、フォーマット)で扱ってね!」と言うような設定をしています。細かい設定内容は下記に記載させていただきます。
'projection.enabled' = 'true'
'projection.day.type' = 'date'
'projection.day.format' = 'yyyy/MM/dd'
'projection.day.range' = '2025/01/01,NOW'
2025/01/01〜NOW(このテーブルにクエリを叩く日付)で指定しています'projection.day.interval' = '1'
'projection.day.interval.unit' = 'DAYS'
'storage.location.template' ='s3://<バケット名>/AWSLogs/<アカウントID>/GuardDuty/<リージョン>/${day}/'
クエリは自身が分析したい内容のクエリを実行してください。今回は冒頭で示した通り、下記シナリオでクエリを実行します。
例)2025/08/15〜2025/08/21の発生しているGuardDutyの重要度Highのアラート件数を検索する
SELECT
COUNT(*) AS critical_count
FROM <DB名>.<Table名>
WHERE day BETWEEN '2025/08/15' AND '2025/08/21'
AND CAST(severity AS DOUBLE) BETWEEN 7 AND 8.9;※<DB名>、<Table名>はそれぞれ作成したDB、Tableの値を記載してください。
いかがでしょうか?
今回はGuardDutyのログ分析をAthenaを用いて行ってみました。応用すれば、S3に溜まっている、他のサービスのログも分析できると思いますので、ぜひ色々試してください!