AWS LambdaのScheduled Eventを使ってバッチ実行してみた
shimo
デロイト トーマツ ウェブサービス株式会社(DWS)公式ブログ

最近、案件でデータ分析を行う機会があり、業界で注目されているデータ分析プラットフォームの一つであるDatabricksを触ってみました。
Databricksは、Apache Sparkの創設者たちによって2013年に設立された企業が提供する統合データ分析プラットフォームです。(詳細はこちら)
以下のような特徴を持っています。
本記事では、Databricksの基本的な機能を試してみた記録を共有します。特に、データガバナンスの要となるUnity Catalogの機能に焦点を当てて、実際の操作手順をまとめています。
まずはアカウントとワークスペースを作成します。
ワークスペースとは、Databricksアセットを操作するための統合環境です。AWSにおけるマネジメントコンソール、AzureにおけるAzureポータルのような位置付けです。(詳細はこちら)
DataBricksのホームページから無料トライアルを選択します。

今回は検証用途につき[クイックセットアップを続行]を続行を選択します。
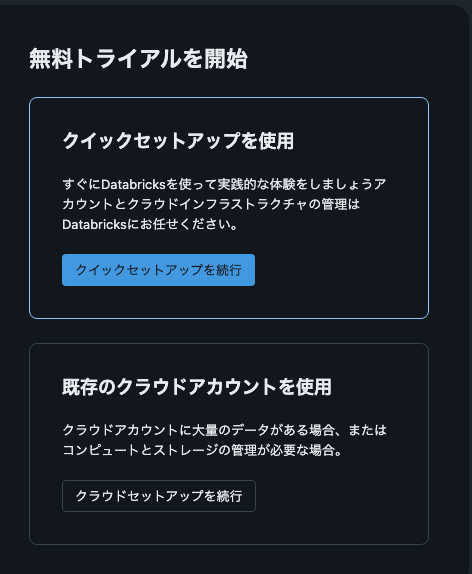
画面の流れに従って任意のメールアドレス入力→認証コードを入力→アカウント名を入力→拠点(国)を指定→ロボット認証後を実施すると、ワークスペースのトップページが表示されます。
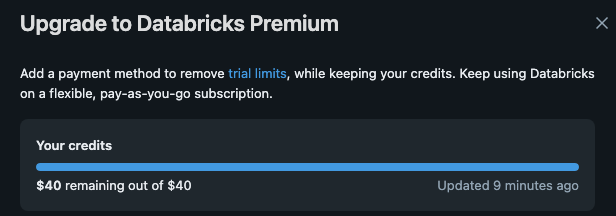
画面右上の[Manage Trial]を選択肢、無料トライアル用のクレジットが適用されていることを確認します。
トライアル用のクレジット額は変動する可能性があるため、検証時に必ず確認するようにしましょう。
必要に応じて左ペインの[Alerts]から予算アラートを作成して下さい。
後続の手順で検証を行うためのノートブックを作成して動作確認を行います。
ノートブックは、Databricks上でデータ分析や機械学習を行うためのインタラクティブな作業環境です。(詳細はこちら)
利用者は、ノートブックを利用することでSQL、Python、Scala、Rなどの言語と使ってデータのクエリや分析、処理を記述できます。Jupyter NotebookやGoogle Colabを利用したことがある方であれば、同じような感覚で利用できるかと思います。
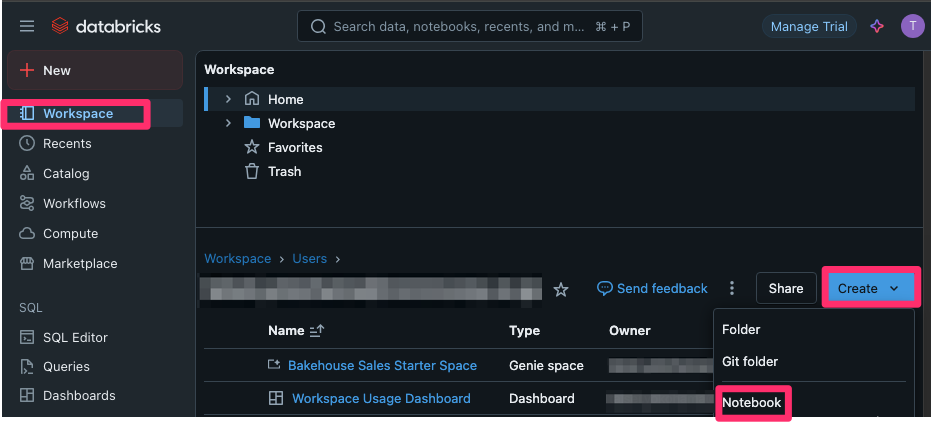
ワークスペースのトップページ左ペインから[Workspace] - [Create]- [Notebook]を選択します。
動作確認として、以下の流れで簡単なPythonプログラムを実行します。
なお、初回は実行環境の起動のために1分程度の読み込みが発生します。
print("Hello World")を記述します。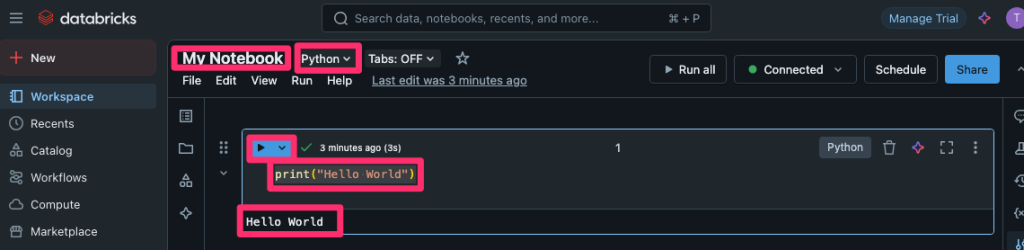
続いて、以下の流れでSQLクエリも実行してみましょう。
%sql
SELECT 'Hello World';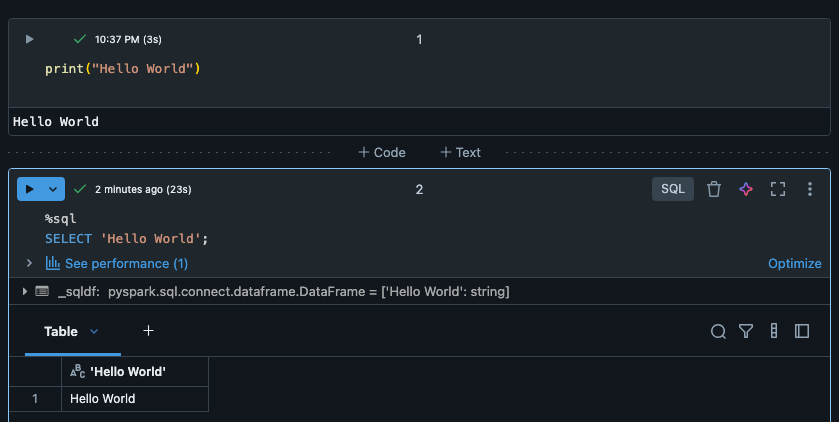
動作確認は以上です。ノートブック上で簡単にプログラムやSQLを実行できることがわかりました。
各コードブロックは不要につき、ゴミ箱アイコンを押下して動作確認用コードを削除して下さい。
DataBricksに登録されているサンプルデータセットから、検証用のUnity Catalogにデータを登録します。
Unity Catalogは、Databricksが提供する統合的なデータガバナンス基盤です。(詳細はこちら)
利用者は、Unity Catalogを利用することで各種データについて「どこに何があるか」「誰がどのようにアクセスできるか」「どのように利用されたか」を管理することができます。
Unity Catalogは、以下に示す要素から構成されます。登場人物として認識して下さい。
DataBricksがデータウェアハウス、データレイクと一線を画す点の一つとして、図の最下部に記載した構造化、半構造化、非構造化データを1つのプラットフォームでまとめて扱えることが上げられます。特徴として抑えておきましょう。
Unity Catalog …データガバナンス・メタデータ管理のカタログ
└── Schema…カタログ内でデータを管理する論理的な区分。データベース。
└── Table / View / Model/ Function / Volume…Schemaで扱う各データ(構造化、半構造化、非構造化データ)検証用のUnity Catalogにデータを登録していきます。まずはノートブックで以下Pythonコマンドを実行し、サンプルデータセットの一覧を表示します。以降、記事内のコードは検証用のノートブックで実行するものとします。
display(dbutils.fs.ls('/databricks-datasets'))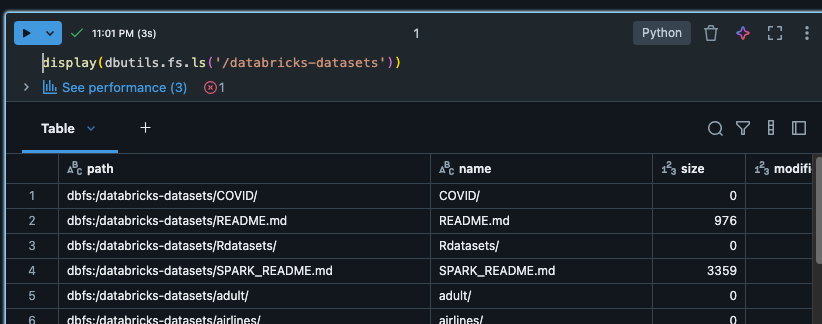
サンプルデータセットのうち、自転車シェアリングに関するデータセットを取得して数レコード表示します。
# データの読み込み
bike_sharing_df = spark.read.csv("/databricks-datasets/bikeSharing/data-001/hour.csv", header=True, inferSchema=True)
display(bike_sharing_df.limit(5))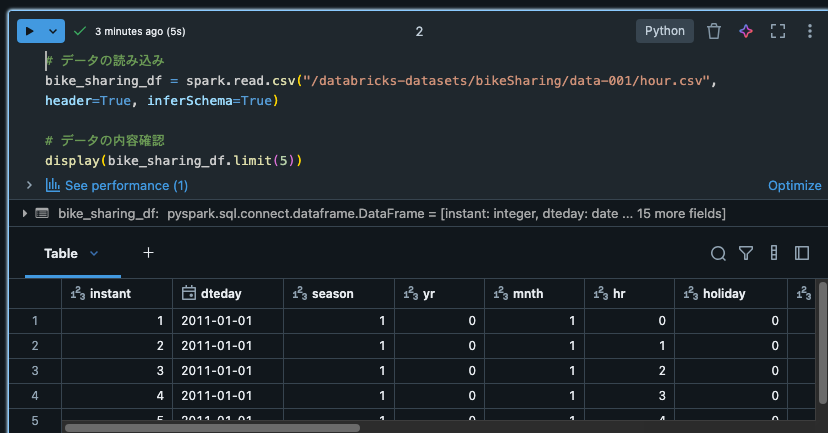
テストデータセットを格納するためのカタログとスキーマを作成します。
%sql
CREATE CATALOG IF NOT EXISTS bike_sharing_catalog;
-- スキーマの作成
USE CATALOG bike_sharing_catalog;
CREATE SCHEMA IF NOT EXISTS rental_data;テスト用データセットから読み込んだデータフレームを、テーブルhourly_rentalsとしてUnity Catalogに登録します。
# カタログとスキーマの指定
catalog_name = "bike_sharing_catalog"
schema_name = "rental_data"
# テーブルの登録
bike_sharing_df.write.format("delta").mode("overwrite").saveAsTable(f"{catalog_name}.{schema_name}.hourly_rentals")ワークスペースを確認すると、UnityCatalog・Schema・Tableが作成されていることが確認できます。
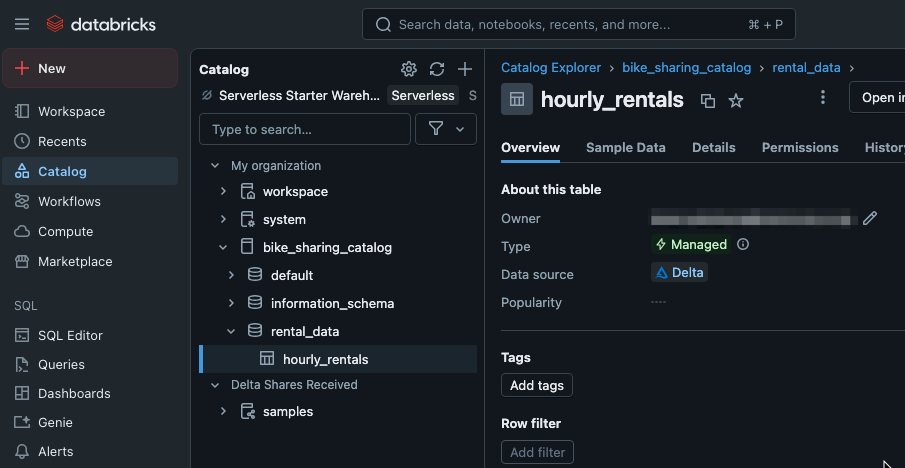
各要素は、本節の冒頭で示した構造に照らすと以下の関係になっています。
Unity Catalog …bike_sharing_catalog
└── Schema…rental_data
└── Table…hourly_rentalsNotebookを使用して、登録したデータを可視化してみます。
本記事では、データの可視化とプロファイルを用いた確認を行います。
%sql
-- 時間帯別の平均レンタル数
SELECT
hr as hour_of_day,
AVG(cnt) as avg_rentals,
AVG(CASE WHEN workingday = 1 THEN cnt END) as avg_workday_rentals,
AVG(CASE WHEN workingday = 0 THEN cnt END) as avg_holiday_rentals
FROM bike_sharing_catalog.rental_data.hourly_rentals
GROUP BY hr
ORDER BY hr;
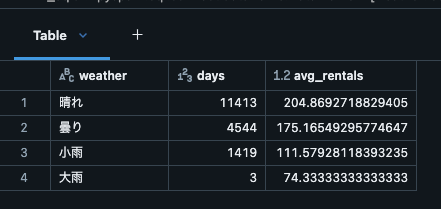
-- 天候状況別のレンタル数
SELECT
CASE
WHEN weathersit = 1 THEN '晴れ'
WHEN weathersit = 2 THEN '曇り'
WHEN weathersit = 3 THEN '小雨'
WHEN weathersit = 4 THEN '大雨'
END as weather,
COUNT(*) as days,
AVG(cnt) as avg_rentals
FROM bike_sharing_catalog.rental_data.hourly_rentals
GROUP BY weathersit
ORDER BY weathersit;クエリの実行結果より、天候別の日数と平均レンタル数が出力できました。
雨の日に自転車を借りるのは危ないのでやめましょう。
[Table]タブ右側の[+]ボタンを押下し、[Visualization]を選択します。
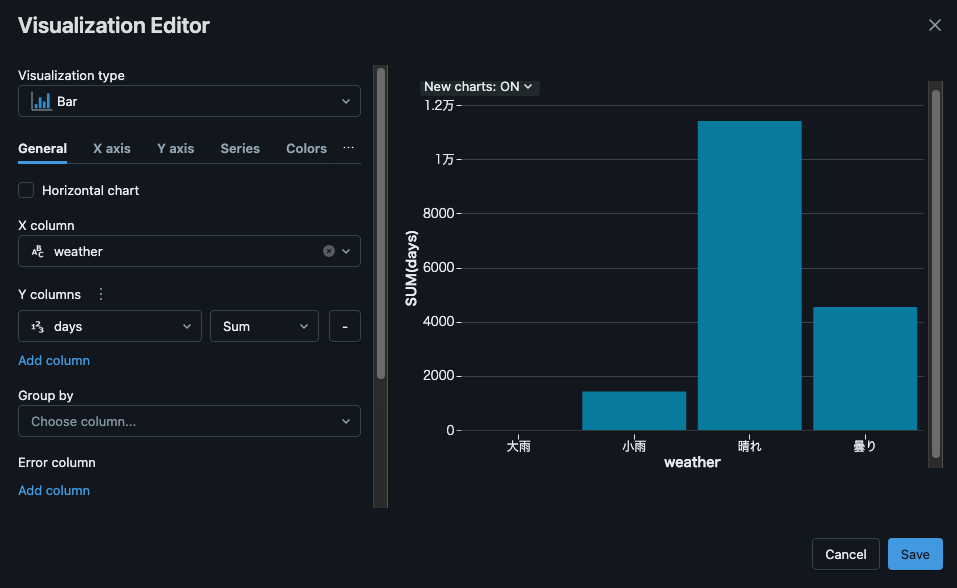
Visualization Editorにて以下の通り入力し[Save]を押下し、天気と日数を帯グラフとして表示できます。
可視化のタイプには棒グラフ、バブルチャートなど様々なものがあり、目的に応じたデータ整形が可能です。(可視化の種類はこちら)
先ほどと同様に[+]ボタンを押下し、[Data Profile]を選択します。
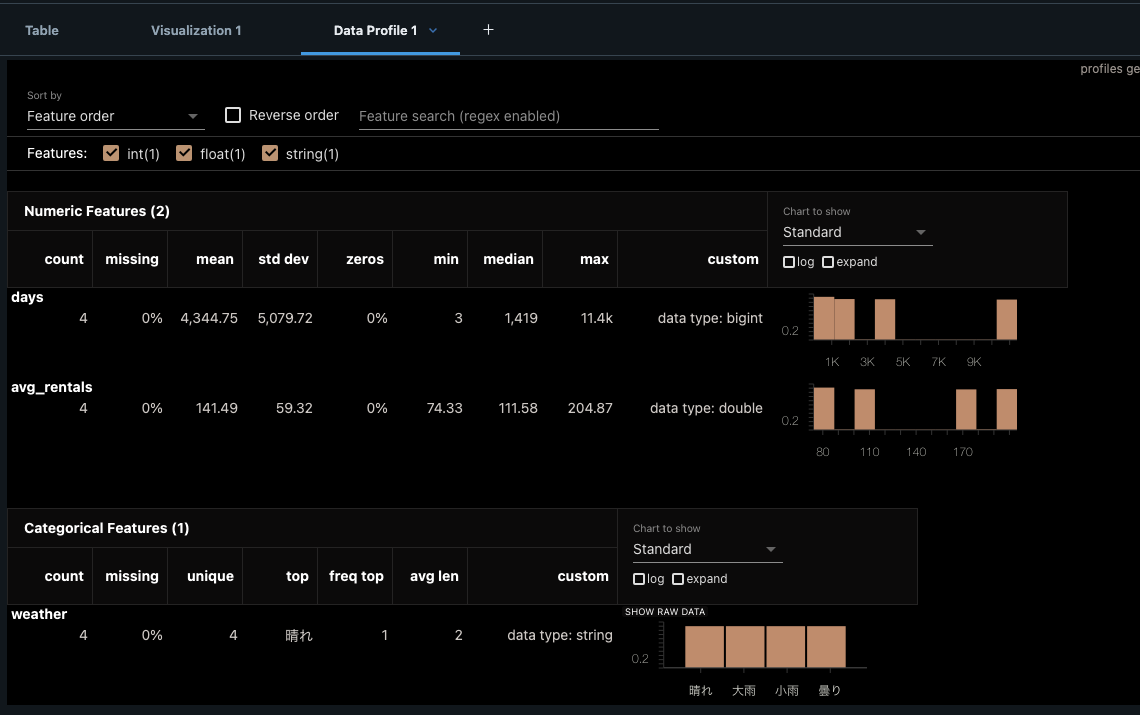
テーブル内の全てのカラムのデータ分布などを確認することが可能です。
確認は以上です。様々な切り口からの可視化ができるので、気になる方がいたら試してみて下さい。
各要素は子要素があると削除に失敗するため、削除は必ず「テーブル → スキーマ → カタログ」の順序で行って下さい。
%sql
DROP TABLE bike_sharing_catalog.rental_data.hourly_rentals;下記の他に「information_schema」というスキーマも存在しますが、これはシステム所有のスキーマのため削除ができません。カタログの削除に影響しないため無視して問題ありません。
%sql
DROP SCHEMA bike_sharing_catalog.rental_data;
DROP SCHEMA bike_sharing_catalog.default;%sql
DROP CATALOG bike_sharing_catalog;以下の画面から[Move to Trash]を選択します。削除確認画面で対象を確認の上で削除を実行します。
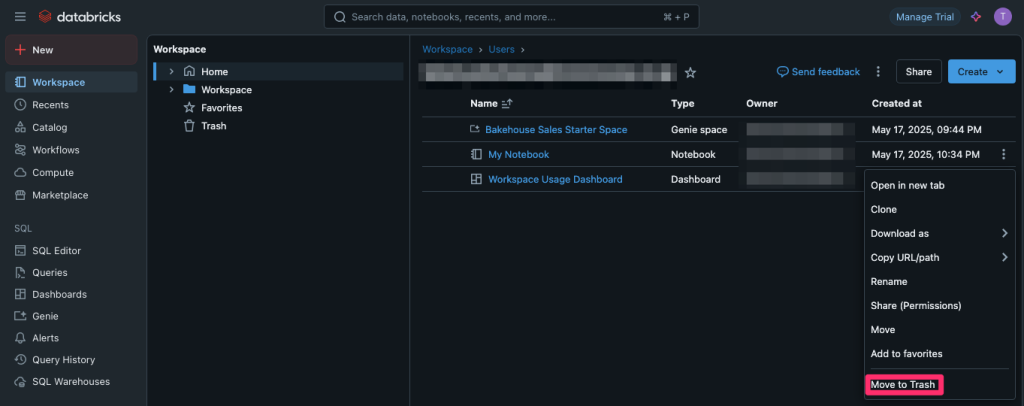
Trash欄から[Permanently delete]を選択します。

ワークスペースの数だけ上記を実施して下さい。
以下の画面から[Delete]を選択します。
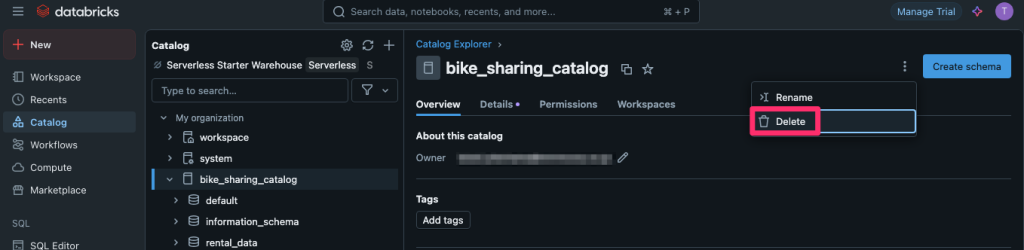
リソースの削除が完了しました。
DataBricksの基本的な機能を使ってデータの可視化ができて楽しかったです。
機会があれば、パイプラインを用いた分析やAI(Genie)を使った分析もやってみたいと思います。