Material for MkDocs をAWS CDKとGitHub Actionsで公開する
yassan
デロイト トーマツ ウェブサービス株式会社(DWS)公式ブログ

こんにちは、yuuchanです。
前回の投稿に続きバックエンドをメインで担当しており、Go言語を使用してAPI処理やバッチ処理を行うLambdaの実装を行っています。
担当しているプロジェクトにおいて、インターネット上に公開されているあるAPIから数万〜のデータを取得し、それらをDynamoDBおよびAurora(Aurora MySql)に書き込む機能を実装しましたが、その際にどのようなアーキテクチャを採用したかやどのような点に注意して機能を実装したかを抜粋して紹介しようかと思います。
将来的に他のAPIからもデータを取得する必要が出てきたり、自システム内でデータを作成して各DBに書き込む必要が出てきたりする可能性があり、それらを踏まえて検討した結果、まずDynamoDBにデータを書き込み、そこから出力されたStreamを用いてAuroraにデータを追加するアーキテクチャを採用することになりました。
以下にアーキテクチャイメージを紹介いたします。
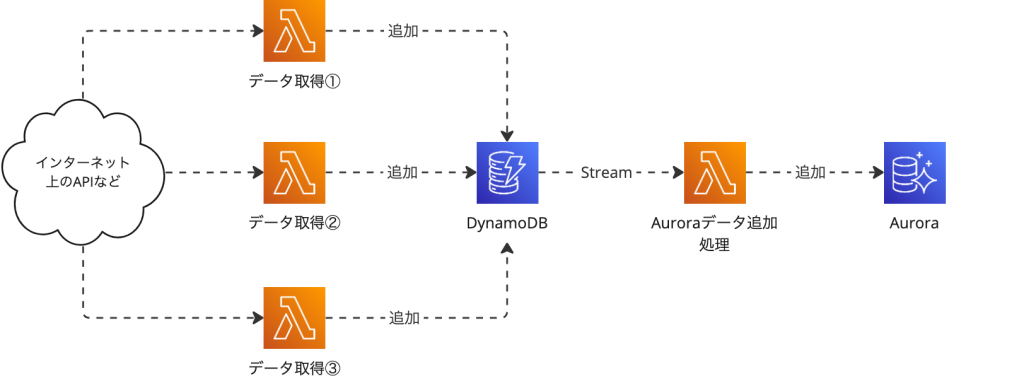
将来的に追加されるであろうデータ取得元は「データ取得①〜③」として表現してあります。
DynamoDBに書き込む元のデータのソースが増えた場合それに対応する取得処理を追加する必要はありますが、Auroraへのデータ追加処理は上記1つのみで対応が可能です。
次にDynamoDB Streamを使用するために必要な設定を紹介します。
AWSのWebコンソール画面からStream機能をオンにしたいテーブルの設定画面を表示し、「エクスポートおよびストリーム」タブを選択します。
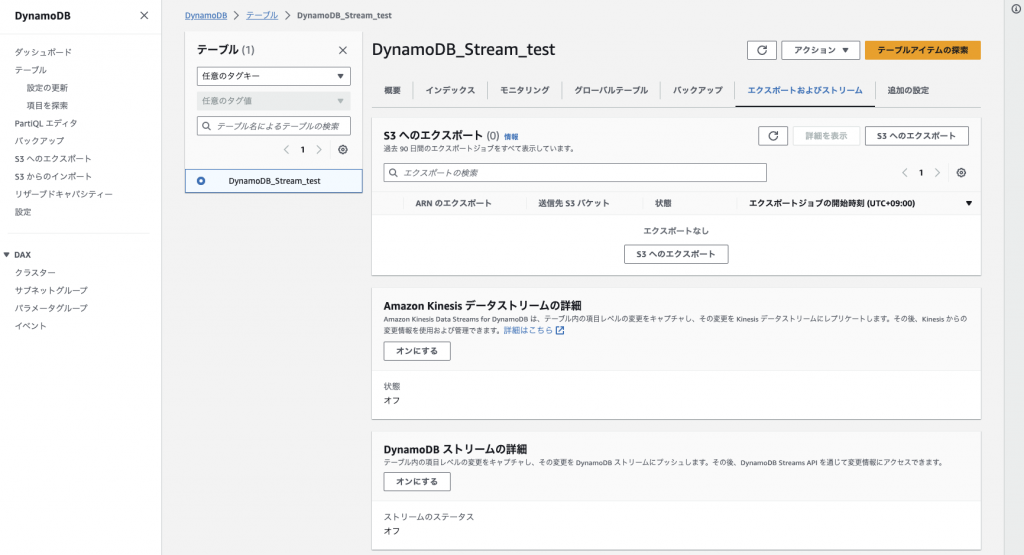
「DynamoDBストリームの詳細」->「オンにする」を選択し、以下設定画面を開きます。
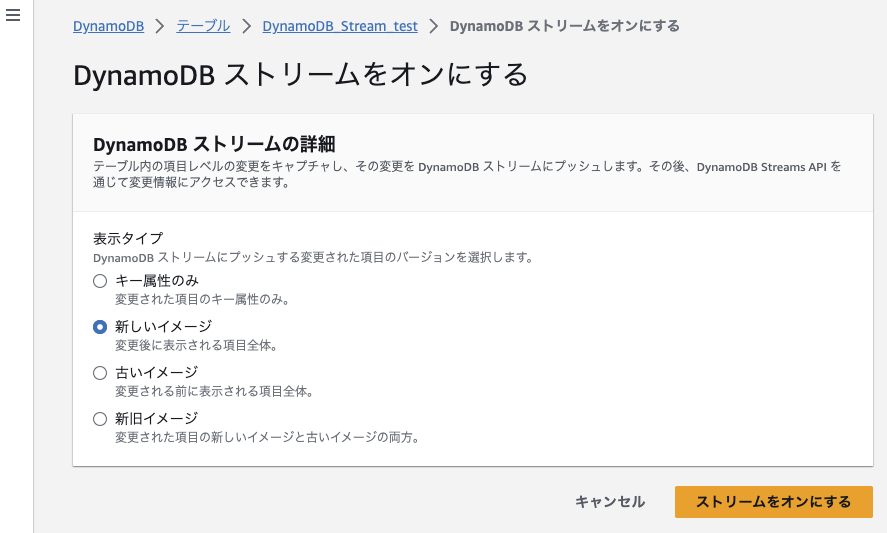
上記では、どのようなデータをDynamoDB Streamにプッシュするか、アーキテクチャ図の言葉を借りるとすると、どのようなデータを「Auroraデータ追加処理」Lambdaに渡すかを設定することができます。
今回DynamoDBにはデータの追加のみを行う想定であるため、「新しいイメージ」を選択しました。
PKやSKのみStreamにプッシュできれば良い場合は「キー属性のみ」、DynamoDBのデータを上書くため変更前と変更後のデータどちらも全てプッシュしたい場合は「新旧イメージ」を選択するようにしてください。
適切な項目をチェックしたら「ストリームをオンにする」を選択し、Stream機能をオンにします。
DynamoDB Stremaの設定は以上です。
Auroraにデータ追加処理を行うLambdaは、DynamoDB Streamへのプッシュをトリガとして動作するように設定します。
Lambdaのトリガの設定画面から「DynamoDB」を選択し、適切な設定値を入力し「追加」を選択します。
DynamoDBをトリガとして設定する際の、いくつかの設定項目について紹介します。
※他設定項目詳細につきましては、公式ドキュメントを参照ください。
Batch Size:
Lambdaが実行1回あたりで受け取ることができるDynamoDBの項目数です。
今回1回あたり、多いときで数万程度、少ないときで数百〜数千のデータをDynamoDBに追加する為、Batch Sizeは10,000にしました。
大量のデータがDynamoDBに追加されるのにBatch Sizeが小さいと、スループットの低下原因になります。
適切な値を設定するようにしてください。
Starting Position:
どの位置からStreamにプッシュされたデータを読み込むかを設定します。
一番新しいデータから読み込む場合は「Latest」、時系列順にデータを読み込みたい場合は「Trim horizon」を選択してください。
今回、DynamoDBに追加された順にデータを処理する必要があったため、「Trim horizon」を選択しました。
Filter Criteria:
Streamにプッシュされたデータすべてを「Auroraデータ追加処理」Lambdaで扱わず、ある一定の条件を満たしたデータのみ扱いたい場合、こちらの項目にその条件を追加します。
今回DynamoDBに「追加」されたデータのみを扱う必要があったため、そのような条件を追加しました。
またDynamoDB上で所謂メタデータのような値も管理しており、そのようなデータはLambdaで扱う必要が無いため、「AttributeにXXXXという項目が存在するデータ」(メタデータにはXXXXというAttributeは存在しない)という条件を追加しました。
このような場合の条件式は以下のようになります。
{
"eventName": ["INSERT"],
"dynamodb": {
"NewImage": { "XXXX": { "S": [{ "exists": true }] } }
}
}Auroraデータ追加処理はGo言語で実装します。
Auroraデータ追加処理でやりたいことは以下のとおりです。
1. Stremaから受け取ったデータを構造体にマッピングする
2. Auroraに書き込む
今回、Streamから受け取ったデータを構造体へマッピングする流れについて紹介します。
マッピング後のAurora(などのRDB)への書き込みにつきましては、使用するライブラリによっても若干違いがあると思いますので本記事では省略いたします。
Lambdaで受け取ったStreamからのデータは以下のような構造になっています。
※一部値を省略・編集しています。
{
"Records": [
{
"awsRegion": "ap-northeast-1",
"dynamodb": {
"ApproximateCreationDateTime": 1689859823,
"Keys": {
"PK": { "S": "1111111" },
"SK": { "S": "2222222" }
},
"NewImage": {
"Id": { "N": 1 },
"Name": { "S": "yuuchan" },
"Age": { "N": 17 },
"Height": { "N": 170 },
"Weight": { "N": 50 }
},
"SequenceNumber": "10700000000000744643908",
"SizeBytes": 944,
"StreamViewType": "NEW_IMAGE"
},
"eventID": "XXXXX",
"eventName": "INSERT",
"eventSource": "aws:dynamodb",
"eventVersion": "1.1",
"eventSourceARN": "arn:aws:dynamodb:ap-northeast-1:〜"
},
{ ... }, // 2つめの項目
{ ... }, // 3つめの項目
...,
{ ... } // Nつめの項目
]
}Recordsの中に、追加された項目が複数入っているような構造です。
SequenceNumberやeventIDなど様々な情報が入っていますが、必要な値はRecordsの中の各項目毎のNewImage内の値です。
NewImage内を見てみると、Attributeの名称と値に加えて型情報も「"N"や"S"」のように入ってきており、単純なjson.Unmarshalでは構造体にマッピングができません。
そこで今回は、github.com/aws/aws-lambda-go/eventsgithub.com/aws/aws-sdk-go/service/dynamodbgithub.com/aws/aws-sdk-go/service/dynamodb/dynamodbattribute
といったライブラリを用いて、以下のようなコードを記述しました。
type Data struct {
ID int64 `dynamodbav:"Id"`
Name string `dynamodbav:"Name"`
Age int64 `dynamodbav:"Age"`
Height int64 `dynamodbav:"Height"`
Weight int64 `dynamodbav:"Weight"`
}
func InsertData(stream events.DynamoDBEvent) error { // stream: DynamoDB Streamから受け取ったデータ
// DynamoDB StreamのデータをData構造体にマッピングする
var newImages []Data
for _, record := range stream.Records {
newImage, err := unmarshalStreamImage(record.Change.NewImage)
if err != nil {
return errors.WithStack(err)
}
newImages = append(newImages, newImage)
}
// Auroraなどへの書き込み処理をここに追記する
return nil
}
func unmarshalStreamImage(attribute map[string]events.DynamoDBAttributeValue) (Data, error) {
var image Data
attributeMap := make(map[string]*dynamodb.AttributeValue)
for name, value := range attribute {
var attribute dynamodb.AttributeValue
bytes, err := value.MarshalJSON()
if err != nil {
return image, errors.WithStack(err)
}
err = json.Unmarshal(bytes, &attribute)
if err != nil {
return image, errors.WithStack(err)
}
attributeMap[name] = &attribute
}
err := dynamodbattribute.UnmarshalMap(attributeMap, &image)
if err != nil {
return image, errors.WithStack(err)
}
return image, nil
}Data構造体の各フィールドにはdynamodbavタグを用いてDynamoDBのAttributeの名称を記述するようにしてください。
項目毎にunmarshalStreamImage()が呼び出され、Attribute毎にunmarshalStreamImage()内のループ内の処理が行われているイメージです。
最終的に、unmarshalStreamImage()のdynamodbattribute.UnmarshalMap()によって、Data構造体の型を持った変数に、1項目分のデータが格納されます。
項目毎のループ処理が終わりnewImages内に全ての項目が格納されれば、あとはnewImageの値をAurora(などのRDB)に書き込むのみです。
いかがでしたでしょうか。
DynamoDB Streamを用いることにより、将来的な変更や追加を最小限にした上でDynamoDBとAuroraに同等のデータを書き込む仕組みを作成することができました。
DynamoDBへのデータ追加元が増えた場合でも、Auroraデータ追加処理は影響を受けません。
またDynamoDBへのデータ追加と、Auroraへのデータ追加の話を切り離して考えることができるため、テストのしやすさは勿論、何らかの問題が起きた場合の原因特定のしやすさやにもメリットがあります。
今後も引き続きAWSの各サービスを使用した際の手順やポイント、Go言語で処理書いた際のTipsを紹介していこうかと思います。