E2Eテストについて考えてみた
mmmuser
デロイト トーマツ ウェブサービス株式会社(DWS)公式ブログ

こんにちは、yuuchanです。
最近Deep Learningの入門書を読みつつ、書かれているようなコードをGPUプログラミングで実装するとどの程度実行が高速になるのか気になり試してみました。
今回この記事では、Windows上で動かしているコンテナからGPUリソースにアクセスして、数万×数万の行列同士の積を計算するまでをご紹介いたします。
Windows 11 + 最新のNvidia GeForce グラフィックスドライバで驚くほど簡単にGPUリソースにアクセス可能ですので、興味がございましたら是非試してみてください。
Docker Desktopをインストールしていない場合、こちらを参考にインストールします。
※WSL 2ベースのエンジンを有効にしてください
CuPyはNvidiaのGPUを使用して数値計算を行う際に使用されるPythonライブラリで、同じく数値計算を行う際によく使用されるNumPyライブラリと高い互換性を持っています。
NumPyを用いて記述するコードのほとんどをCuPyを用いて記述することができ、数値計算を簡単にGPUに実行させることができます。
今回は、CuPyコンテナイメージを用いて起動したコンテナ上でNumPyおよびCuPyを使用した数値計算のプログラムを書き、実行およびかかった時間の比較を行いたいと思います。
CuPyコンテナイメージのダウンロードおよび実行は、公式ドキュメントに記載のある通り以下のコマンドで行うことができます。
docker run --gpus all -it cupy/cupy /bin/bash
既にCuPyコンテナイメージがローカルにダウンロードしてある場合は、そのイメージを用いてコンテナが起動されます。
イメージがローカルにない場合は、ダウンロードされた上でコンテナが起動されますので、少々待ちましょう。
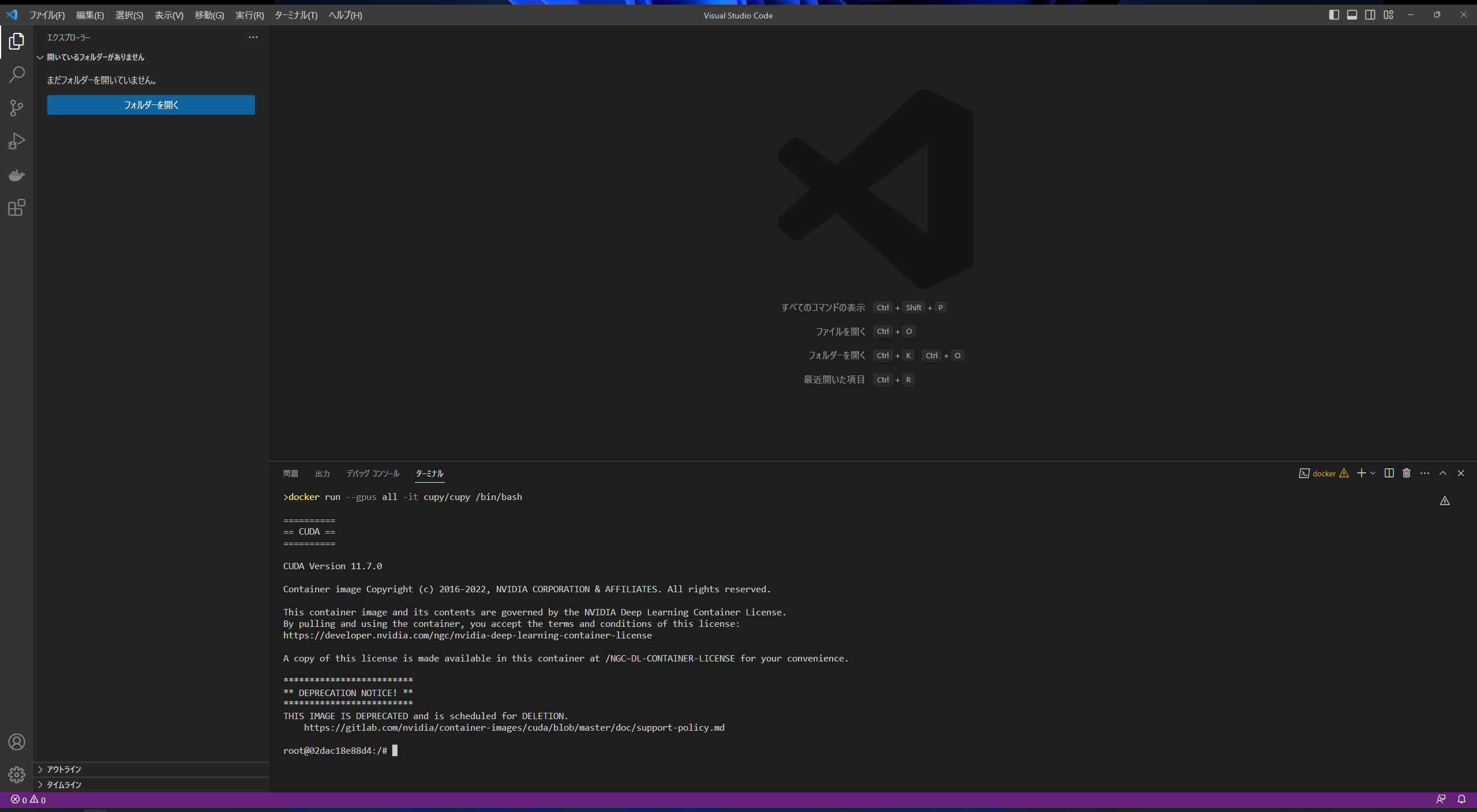
コンテナが起動されると、以下のようにコンテナ内に入った状態になります。
今回、Pythonのプログラムを書き前節で起動したコンテナ上でそれを実行します。
その方法はいくつかありますが、Visual Studio Code(以下、VS Code)の「Dev Containers」を使用してコンテナ内のPythonファイルを直接VS Codeで作成・編集し実行してみます。
左下の隅にある緑色の「><」を選択し、「Attach to Running Container...」を選択します。
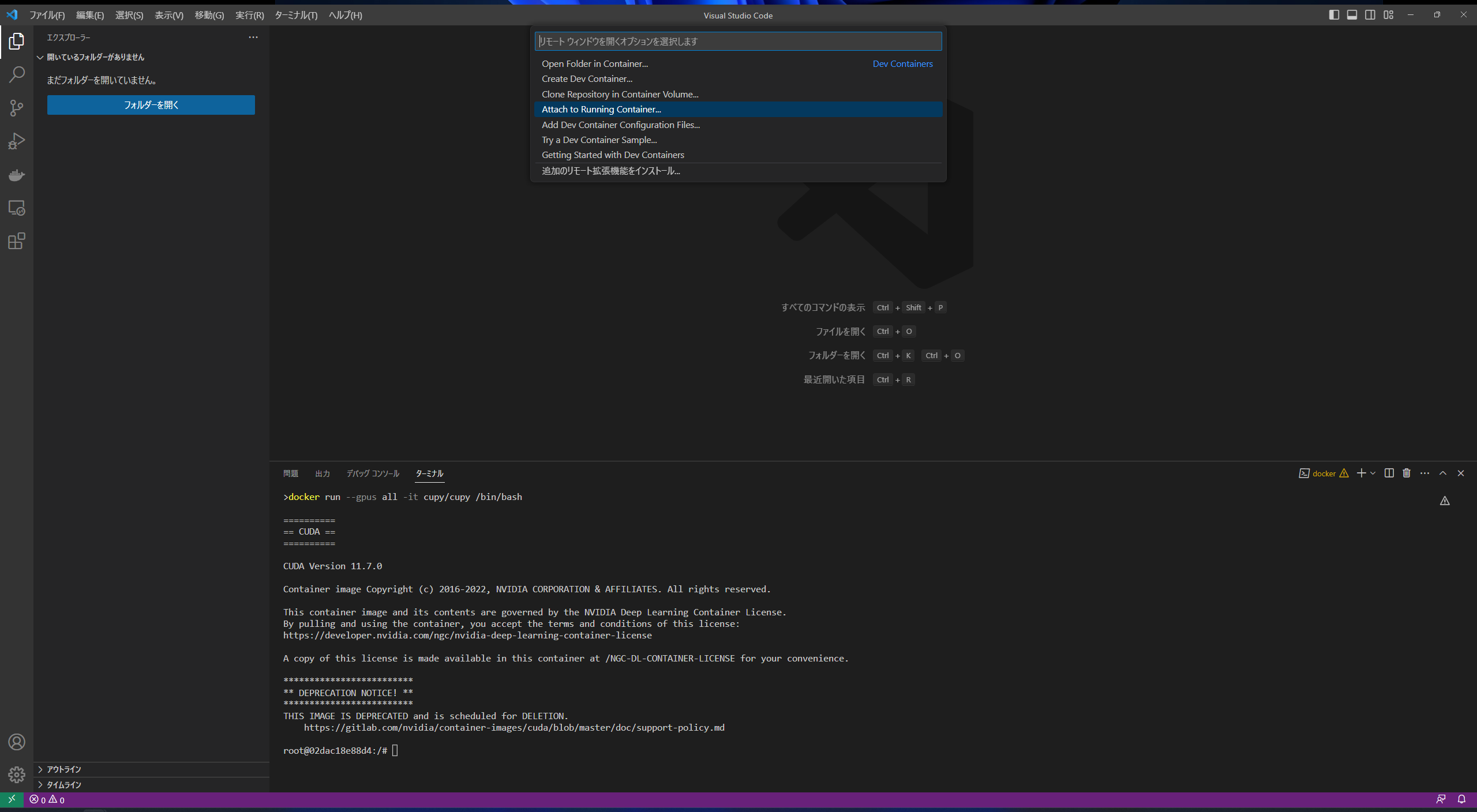
前節で起動したコンテナを選択します。
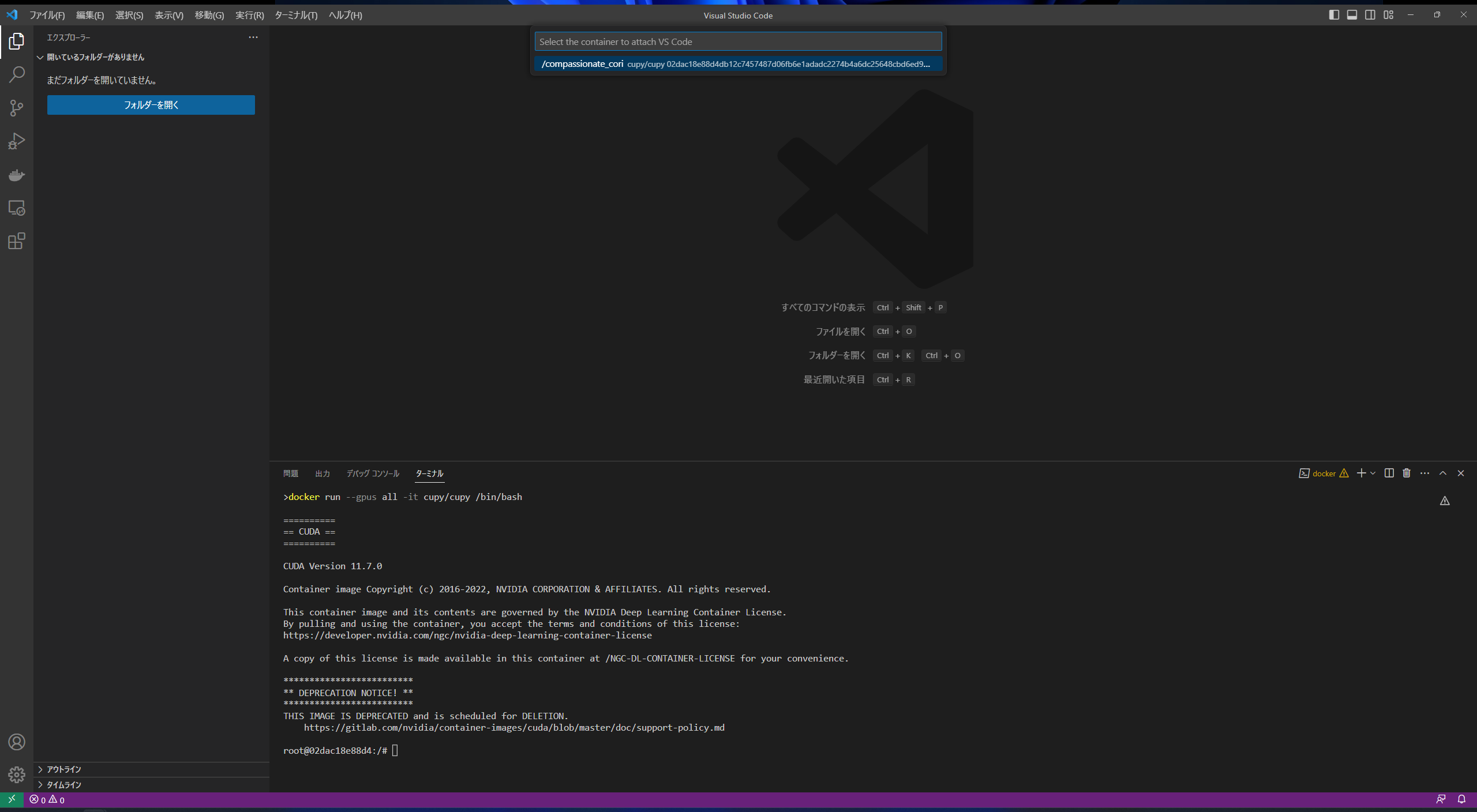
新しいVS Codeウィンドウが開くので、左側の「フォルダーを開く」を選択すると、コンテナ内のディレクトリから任意のフォルダを開くことができます。
今回は仮に「/root」を開きます。
matrix_calc.py
import numpy as np
import cupy as cp
import time
# 行列AおよびBの生成
matrix_A = np.random.randn(10000, 20000)
matrix_B = np.random.randn(20000, 30000)
# CPUでの数値計算
start = time.time()
matrix_AB = np.dot(matrix_A, matrix_B)
end = time.time()
print("CPUでの数値計算:", end-start)
# 2つの行列値をGPUメモリへ移動
start = time.time()
matrix_A_gpu = cp.asarray(matrix_A)
matrix_B_gpu = cp.asarray(matrix_B)
end = time.time()
print("メインメモリ->GPUメモリ:", end-start)
# GPUでの数値計算
start = time.time()
matrix_AB_gpu = cp.dot(matrix_A_gpu, matrix_B_gpu)
end = time.time()
print("GPUでの数値計算:", end-start)「np.dot()」「cp.dot()」のように、NumPyで行列積を計算する際とCuPyで行列積を計算する際の記述は全く同じです。
これは前述の通り、CuPyライブラリがNumPyライブラリと高い互換性を持つように作成されているからです。すごい!
以下コマンドでPythonのプログラムを実行します。
python3 matrix_calc.py
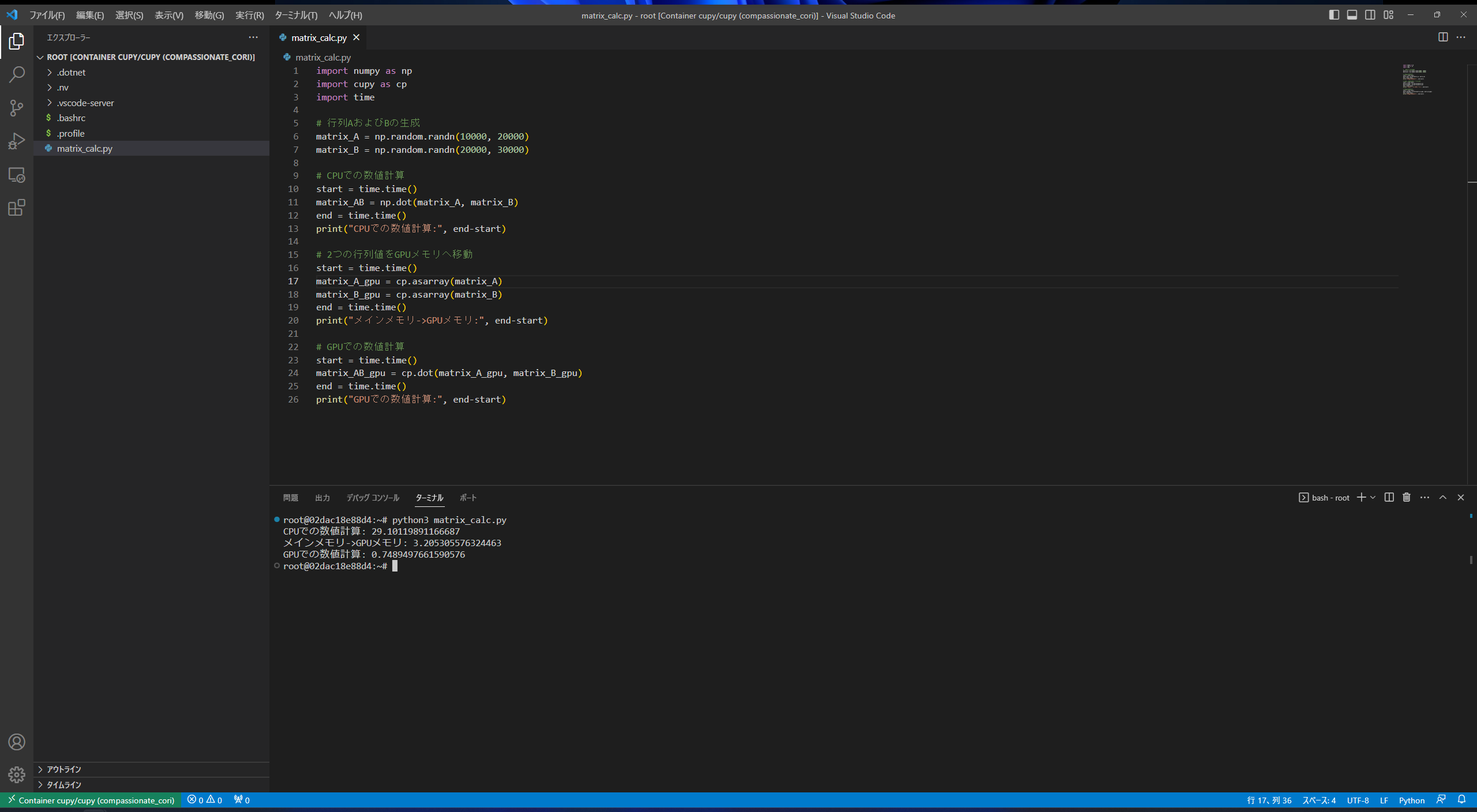
今回、「CPUでの数値計算」「2つの行列値のGPUメモリへの移動」「GPUでの数値計算」の3処理にてそれぞれ処理時間を計測しました。
| 処理内容 | 処理時間 |
|---|---|
| CPUでの数値計算 | 約29.10秒 |
| GPUメモリへの移動 | 約3.21秒 |
| GPUでの数値計算 | 約0.75秒 |
計算を行う行列のGPUメモリへの移動に3.21秒ほどかかっていますが、実際の数値計算はCPUと比べてGPUの方が約40倍速く行うことができています。
小さいサイズの行列の計算を行う場合はCPUで計算してしまった方が速い場合もありますが、今回用意したような十分大きなサイズの行列の計算を行う場合は並列演算性能が優れているGPUを使用した方がより速く計算を行うことができます。
いかがでしたでしょうか。
GPUを使用したプログラミングと聞くと難しいイメージをお持ちの方もいらっしゃるかもしれませんが、今回たったこれだけの手順で「GPUに行列の計算をさせる」ことができました。
もちろん、GPUリソースを有効に活用して数値計算を行うためにはよりGPUプログラミングの理解を深める必要がありますが、ちょっとした計算をGPUリソースを用いて行いたい場合は、今回紹介したような手順で十分色々と試せるかと思います。
それでは、良いGPUプログラミングライフを!





