
AWS ANGEL Dojo2025で最優秀技術賞を獲得しました!
numa
デロイト トーマツ ウェブサービス株式会社(DWS)公式ブログ

こんにちは。よっしぃです。
今回は、データベースの論理設計において重要な「正規化」について整理してみたいと思います。
アプリケーションの設計・開発に関わる方であれば、こうした作業は日常的に行っているかもしれません。私自身も、これまで開発の中で「正規化」をする機会は多々ありましたが、あらためて人に説明しようとすると曖昧な部分があると感じました。
最近、お客様案件で論理データモデルを設計する機会があり、「正規化」についての理解を見直す良いきっかけとなりました。そこで今回は、自分の中での整理も兼ねて、「正規化」の基本から実際の設計ステップまでをまとめてみたいと思います。
「正規化」について触れる前に、データベース設計の基礎を確認しておこうと思います。
データベース設計は、「概念設計」「論理設計」「物理設計」の3段階で進められ、それぞれの過程で「概念データモデル」「論理データモデル」「物理データモデル」が作成されます。
業務要件をもとに、どのような情報を扱うか、それらがどう関係するかを整理します。
「概念データモデル」では、ビジネス視点から、実装を意識せずに、データ同士の関係を抽象的なレベルで表現します。
たとえば、「顧客」は複数回「注文」をし、「注文」には複数の「商品」が含まれる、といった関係を図式化します。
図: 概念設計のイメージ
概念設計で洗い出した情報をもとに、データの構造を論理的に整理し、設計します。
「論理データモデル」を作成し、主キー・外部キーの明確化や「正規化」などを通じて、DBMSに依存しない形で整合性の取れた構造を定義します。
今回のテーマである「正規化」はこのフェーズで実施されます。
論理設計の内容を、実際に使用するDBMSやパフォーマンス要件を踏まえて最適化します。
「物理データモデル」で、データ型や制約、インデックスなどを設計し、テーブル定義書やテーブル作成用SQL文として実装に反映します。
「正規化」とは、データの重複や不整合を防ぐために、データ構造を整理する設計手法です。その基本となる考え方が、データベース設計の重要な原則である
「1つの事実は1つの場所に(One Fact in One Place)」
です。この原則が守られていないと、以下のような問題が発生します。
たとえば、注文データに顧客情報を毎回書き込んでいる場合、顧客の住所が変更された際に、すべての注文データを修正しなければ整合性が取れなくなります。
図: 顧客情報が重複しているイメージ

「佐藤太郎」さんの住所が変更になった場合、顧客名が「佐藤太郎」さんの全てのレコードを一つ残らず更新しなければなりません。
こうした問題を防ぐために、「正規化」では「何が主で、何に従属しているのか」を把握し、情報を適切に分割(テーブル分離)して、一貫性のあるデータ構造を作っていきます。
「正規化」を理解するためには、「主キー」と「関数従属」という2つの考え方を押さえておく必要があります。特に第2正規形以降では、この2つが「正規化」の判断基準になります。
主キーとは、テーブル内の各レコードを一意に特定するための属性(または属性の組み合わせ)です。たとえば、顧客テーブルでは「顧客コード」、商品テーブルでは「商品コード」が主キーとして使われることが一般的です。同じ顧客コードや商品コードを持つレコードは存在できません。
また、テーブルによっては、複数の属性を組み合わせて主キーにする(複合キー)ケースもあります。たとえば、1件の注文に複数の商品が含まれる「注文明細」では、「注文コード」と「商品コード」の組み合わせで1レコードが一意に特定されるため、この2つが複合主キーとなります。
関数従属とは、ある属性(X)の値が決まると、他の属性(Y)の値も一意に決まるという関係のことです。記号で表すと「X → Y」と書きます。
たとえば、次のような関係はすべて関数従属の例です。
関数従属の関係を把握し、「どの属性がどの属性に依存しているか」が明確になり、「正規化」の際にテーブルをどう分けるべきかの判断材料になります。
第2正規形や第3正規形では、以下のような「望ましくない関数従属」を取り除くことが目的になります。
部分関数従属:複合キーの一部だけに依存している属性がある状態。
主キーの一部であるXの値が決まると、Yの値も一意に決まるような場合です。
たとえば、「注文コード+商品コード」が主キーである場合、「注文日」は「注文コード」によって一意に決まるため、「注文コード」に対して「部分関数従属」していると言えます。
{注文コード} → {注文日}
こうした「部分関数従属」がない状態が第2正規形となります。
推移的関数従属:主キーに直接ではなく、主キー以外の属性に依存している属性がある状態。
主キーXの値が決まると、Yの値も一意に決まり、さらにYが決まると、Zの値も一意に決まるような場合です。
たとえば、「注文コード」が決まると「顧客コード」が決まり、「顧客コード」によって「顧客住所」が決まる場合、「顧客住所」は「注文コード」に対して「推移的関数従属」していると言えます。
{注文コード} → {顧客コード} → {顧客住所}
こうした「推移的関数従属」がない状態が第3正規形となります。
これらの関数従属を解消することで、テーブルの構造がより明確になり、更新や参照の際の整合性を保ちやすくなります。
このような前提を理解した上で、次は実際にどのように「正規化」を進めていくのか、ステップごとに見ていきます。
ここからは「正規化」をどのように進めていくのかを、具体的なステップに沿って見ていきます。「正規化」は、一般的に次のような段階を踏んで進められます。
非正規形 → 第1正規形 → 第2正規形 → 第3正規形
さらに細かい正規形(ボイスコッド正規形、第4・第5正規形)もありますが、実務では第3正規形まで行えば十分とされることが多いので、今回も第3正規形までを扱います。
非正規形とは、1つのセルに複数の値が記録されているような状態を指します。
たとえば、1件の注文に複数の商品が含まれる場合、1レコードにそれらをすべて詰め込むと以下のようになります。
図: 非正規形のイメージ

注文コード: 1001
商品コード: P001, P002
商品名: ノートPC, マウス
...
表計算ソフトなどではよく見かける形かと思いますが、このように1つのセルに複数の値があると、リレーショナルデータベースでは、データを正しく扱うことが難しくなります。
第1正規形では、すべてのセルが単一の値を持つようにします。
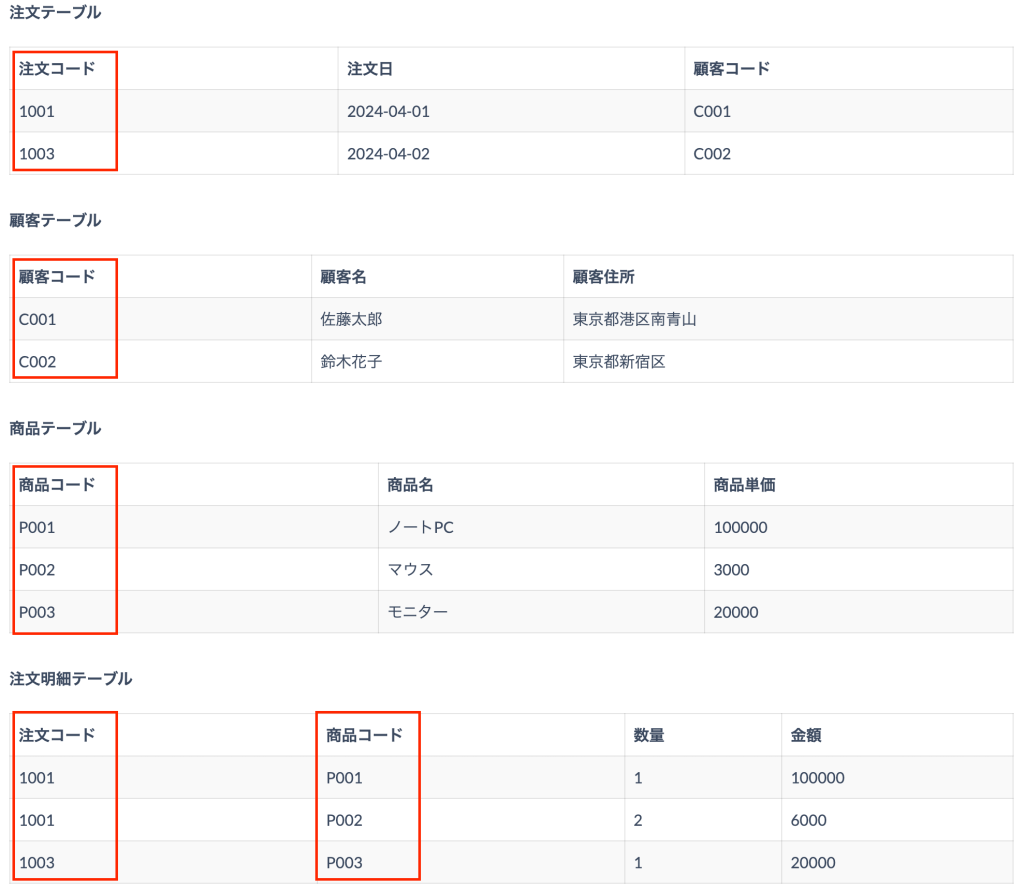
図: 第1正規形のイメージ

このように変形することで、各セルが単一の値となり、リレーショナルデータベースとして有効な構造になります。
また「注文コード」だけでは各レコードを一意に識別できないため、「注文コード」と「商品コード」の複合キー(2つの属性の組み合わせ)を主キーとする必要があります。
第2正規形では「部分関数従属」を解消します。
注文テーブルの主キーは「注文コード + 商品コード」の複合キーです。
「注文コード」にのみ依存、「商品コード」にのみ依存している属性は、複合キーの一部分にのみ依存しているので、このような属性は別テーブルに分けます。
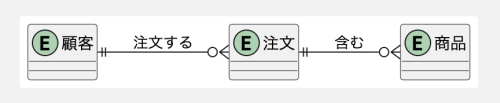
図: 第2正規形のイメージ
※1「金額」は「商品単価」と「数量」から算出できる場合、属性としては保持しないこともあります。
第3正規形では「推移的関数従属」を解消します。
「注文コード」が決まると「顧客コード」が一意に決まり、「顧客コード」が決まると「顧客名」や「顧客住所」が一意に決まるというように、主キー以外の属性(ここでは「顧客コード」)に依存して、他の属性が一意に決まる場合、別のテーブルに分割します。
「推移的関数従属」があると、「顧客名」や「顧客住所」を変更する際に複数レコードの更新が必要になり、整合性の維持が難しくなります。
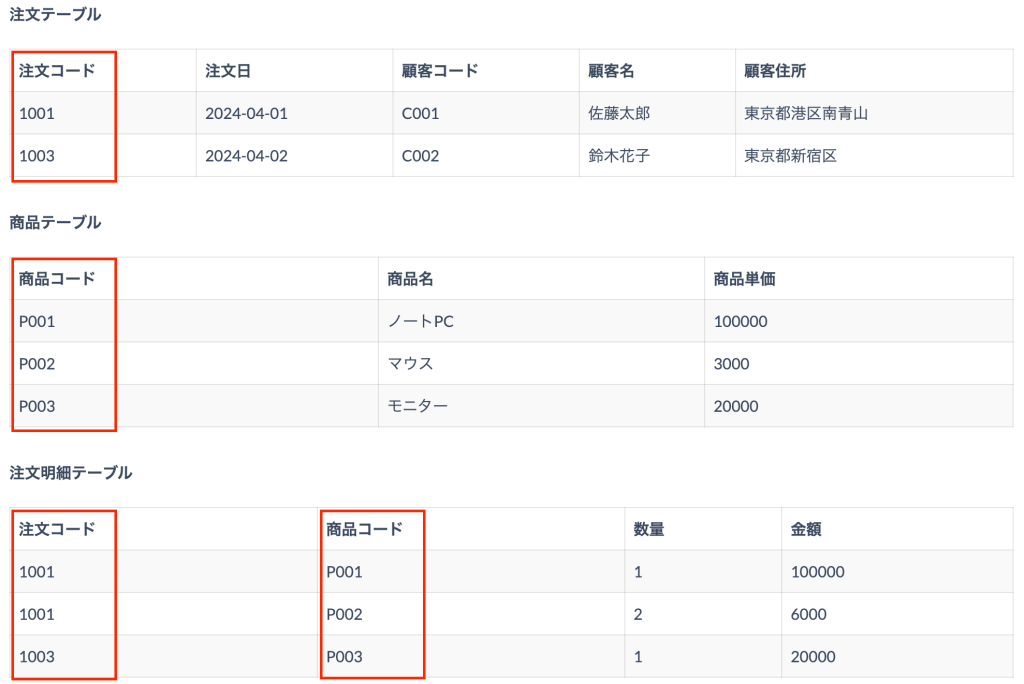
図: 第3正規形のイメージ
これで第3正規形まで到達しました。
「正規化」を通じて、データの重複や不整合を防ぎながら、検索・更新しやすい構造に整えることができます。また、テーブル間の関係が明確になることで、システム全体の保守性や拡張性も向上します。
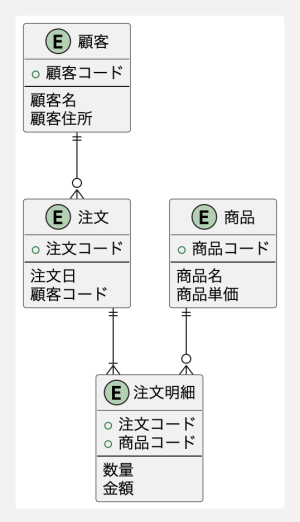
今回作成した第3正規形のER図を以下に示します。
図: 第3正規形のER図
「正規化」は、整合性や保守性を高めるための基本的な手法ですが、実務ではすべてのテーブルに対して、無条件に適用すれば良いというものではありません。この章では、「あえて正規化しない」判断がされる代表的なケースを紹介します。
「正規化」によってテーブル数が増えると、検索時にJOINが多用されるようになります。結果としてクエリのパフォーマンスが低下することもあります。そのため、レポート出力など即時性が求められる場面では、あえて重複を許容したサマリーテーブルや非正規化ビューを使うことがあります。
「正規化」の主な目的は「更新時の不整合を防ぐこと」です。しかし、ログや履歴といった追記のみで更新が発生しないデータであれば、冗長性を許容してでも記録のわかりやすさを優先することがあります。
このように「正規化」はあくまで基本方針であり、要件や目的に応じた柔軟な判断が求められます。
今回は、データベースの論理設計における基本である「正規化」について、基礎知識から具体的な設計ステップ、実務での例外パターンまで整理してきました。
「正規化」は「1つの事実は1つの場所に」という原則のもと、データの重複や不整合を防ぎ、保守性の高い構造をつくるための重要な考え方です。特に、第1〜第3正規形までを適切に適用することで、更新時の異常やデータの冗長性といった問題を防ぐことができます。
一方で、実務では「あえて正規化しない」設計が必要になる場面もあります。パフォーマンスの要件や、更新が発生しないログ・履歴テーブルなど、現場ごとの目的や事情に応じて、柔軟に設計を判断することが求められます。
私自身も日々の業務の中で「正規化」を自然に行ってきましたが、こうしてあらためて整理・言語化することで、設計意図や判断の基準がより明確になったと感じています。この記事が、これからデータベース設計に取り組まれる方や、「正規化」に対する理解を見直したい方の参考になれば幸いです。



