Session Manager 使えば踏み台サーバーが不要に
gene
デロイト トーマツ ウェブサービス株式会社(DWS)公式ブログ

こんにちは、アーノルドです。最近はハイブリッドネットワークの設計・構築・運用をメインの業務として担当させていただいています。今回は、昨年初秋にAWS Direct ConnectとSite-to-Site VPNを組み合わせた環境で遭遇したトラブルについてお話ししたいと思います。
ある日、我々の運用拠点のルーターをいつも通り再起動したら…なんとネットワーク全体がダウン!当社拠点だけでなく、同じAWSアカウントに接続している顧客データセンターのVPNトンネルまで全滅。ルーター1台の再起動が、なぜここまで広範囲に影響したのか?
本記事では、原因究明のプロセス、技術的な背景、そして最終的な解決策を詳しく解説します。特にAWS環境でDirect ConnectとVPNを併用している方々の参考になれば幸いです。
AWSのエキスパートとして、私たちは様々な企業のクラウド移行や運用を支援しています。今回お話しするプロジェクトには、AWS環境のインフラ設計・構築・運用・保守を担当する当社と、大規模なオンプレミスインフラを持つ顧客の2つの主要な役割があります。両者は、Direct Connectをアンダーレイネットワーク(基盤回線)として活用し、その上に構成されたAWSのフルマネージドサービスであるプライベートIP Site-to-Site VPNを使用し、インターネットを経由せずにAWSクラウド環境に接続しています。
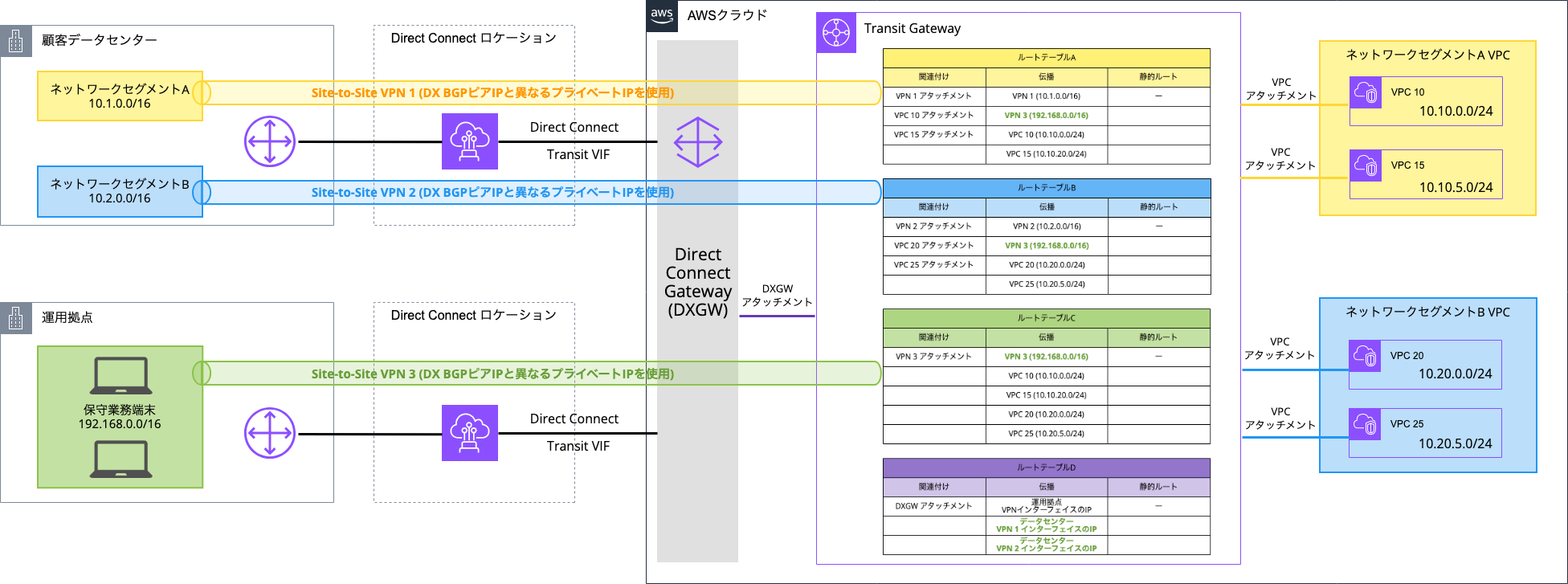
ネットワーク構成は、以下の図のとおりです。
(※実際の構成を簡略化しており、IPアドレスも実際の値とは異なります)

顧客データセンターにはセグメントAとセグメントBの2つのネットワークがあり、セキュリティ要件により相互通信は一切禁止されています。また、顧客ネットワークと運用拠点の両方で通信の暗号化が必須でした。これらの要件を満たすため、AWS Site-to-Site VPNを導入しました。
具体的には、顧客データセンターの各セグメントは専用のVPNトンネルを介してAWSに接続し、分離を維持しつつ暗号化を確保。一方、運用拠点はセグメント間の分離が不要なため、1つのVPN接続で両セグメントにアクセスできる構成としました。
VPN接続はTransit Gatewayで終端し、AWS環境内の複数のVPCにルーティングされます。Direct Connectではトランジット仮想インターフェイス(Transit VIF)を使用し、Direct Connect Gatewayを介してTransit Gatewayに接続。このDirect Connect回線をアンダーレイに、その上にプライベートIP Site-to-Site VPNをオーバーレイとして構成することで、Direct Connect単体では提供されないエンドツーエンド暗号化と、厳格なネットワークセグメンテーションを両立しています。
VPN接続におけるルーティング方式として、データセンター側ではBGPによる動的ルーティングを、運用拠点はシンプルな静的ルーティングを採用しています。
AWS Transit Gateway(TGW)には以下の4つのルートテーブルを設定しました。
また、AWS VPCはそれぞれ適切なルートテーブル(AまたはB)にアタッチされていますが、運用保守拠点からの通信の戻り経路を確保するために、ルートテーブルA・Bの両方に運用保守拠点宛ての静的ルートを追加しました。
ある日、運用拠点のルーターをメンテナンスのために再起動しました。通常であれば、影響を受けるのはその拠点のVPN接続のみのはず。しかし、想定外の事態が発生しました。
なんと、運用拠点だけでなく、顧客データセンターのVPNも含め、すべてのVPNトンネルが同時にダウン。CloudWatchのアラートが両拠点のVPN接続で一斉に発報され、Transit GatewayのルートテーブルではVPN接続のルートがブラックホール化していました。
「なぜ運用拠点のルーターを再起動しただけで、データセンターのVPNまで落ちるのか?」
この疑問を解決するため、徹底的な調査を開始しました。
問題発生後、まずは基本的な確認から着手。運用拠点のルーター設定を精査し、BGP設定、インターフェイス状態、ルーティングテーブル、再起動時のログを詳細にチェック。しかし、異常は見当たらず。
次に、AWS側の設定を徹底確認。Transit GatewayのルートテーブルやBGPステータス、VPNトンネルの状態とルート伝播設定をチェック。それでも決定的な手がかりは得られず。
念のため、CloudWatchのアラーム設定とメトリクスを再確認。Direct ConnectとSite-to-Site VPNの両方について、データセンターと運用拠点の接続が正しく区別されているか、誤って運用拠点の接続をデータセンターの接続として報告していないかを慎重に確認。しかし、残念ながら誤検知ではなく、実際にデータセンターを含む全接続がダウンしていることを確認しました。
そこで、次の仮説を立てました。
「運用拠点のVPNがダウンすると、Transit GatewayのルートテーブルA・Bに設定された静的ルートがブラックホール化し、ルート再計算の影響でTransit Gatewayが一時的に不安定になるのでは?」
検証のため、ルートテーブルA・Bから静的ルートを削除し、ブラックホール化の影響を排除。しかし、状況は変わらず。問題の本質は別のところにあるようでした。
ここでAWSサポートに相談を決断。すると、意外なところに原因があることが判明した。
問題の核心は、Direct ConnectレイヤーのBGPルートのアドバタイズ設定にあったのです。
Direct Connect Gatewayの仕様上、Direct Connect仮想インターフェイス(VIF)から何らかのルートがアドバタイズされている場合に限り、そのVIFのピアIPアドレスへの通信が可能になります。
しかし、データセンターのVIFから、Direct Connect Gatewayに明示的なルートのアドバタイズ設定をしていなかったのです。BGP経由でルートを広報していたのは運用拠点のVIFのみ。
結果として、運用拠点のルーターを再起動すると、VIFのBGPセッションがダウンし、Direct Connect Gatewayへのルート広告が消失(TGWルートテーブルD内のルート数はゼロ)。その影響で、VPNのエンドポイントIPへの到達性が失われ、すべてのVPN接続が一斉にダウンしてしまったのです。
一連のイベントの流れを以下にまとめてみました。
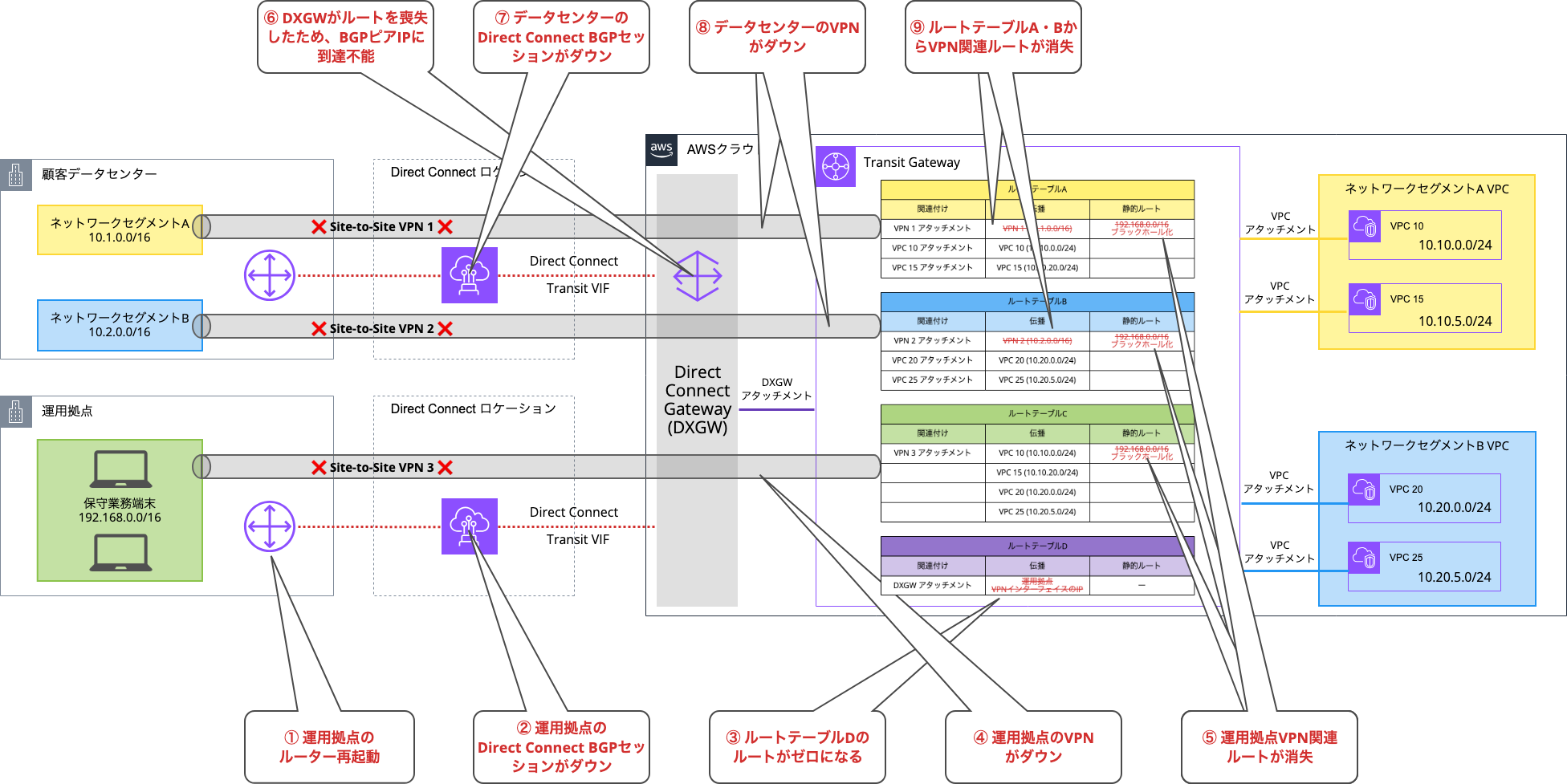
では、なぜこれまで問題が発生しなかったのでしょうか?AWSサポートによると、以前はBGPピアIPが暗黙的に伝播されていたため、ピアIPの明示的な広告を設定しなくてもDirect Connect Gatewayに到達可能でした。しかし、ちょうど問題が発生し始めた時期に、AWSがTransit GatewayのBGPピアIPアドレスの暗黙的伝播をブロックする仕様変更を行いました。この変更により、BGPピアIPが自動的に広報されなくなったため、今回の問題が引き起こされたのです。
さらに、AWSサポートから別の重要なご指摘がありました。VPNのカスタマーゲートウェイIPがDirect ConnectのBGPピアIPと重複していたのです。この点も、AWSの推奨構成から外れていることが分かりました。この設定が原因で、Transit Gateway側のルート処理に影響が出ていた可能性があるので、今後はオーバーレイネットワークでDirect ConnectのBGPピアIPを利用せず、別のIP空間をBGP経由で広告することを推奨していただきました。
原因が特定できたため、すぐに対策を実施しました。
まず、データセンターの事業者には、Direct Connect VIFからDirect Connect Gatewayへのルートアドバタイズを設定するように依頼。これにより、運用拠点のVIFがダウンしても、データセンター側からの経路が維持され、VPNエンドポイントへの到達性が確保されるようになりました。
次に、両拠点のVPNのインターフェイスIPを見直し、Direct ConnectのBGPピアIPと重ならないよう変更。この修正により、Transit Gatewayでのルート処理への影響を排除しました。
ついでに、運用拠点のVPNルーティング方式を静的ルーティングから動的ルーティング(BGP)へ移行することに。これにより、運用拠点への静的ルートが不要となりました。
最終的なネットワーク構成は以下の通りです。
最後に、運用拠点のルーターを再起動し、データセンターのVPNが安定稼働するかを確認。結果、データセンターのVPNは影響を受けることなく、正常に動作しました。
今回のトラブルから、いくつかの重要な教訓を得ることができました。
ルーティングの仕組みを深く理解することが不可欠
特にAWS Transit GatewayとDirect Connectを組み合わせる場合、BGPの動作やルートアドバタイズの影響を事前にしっかり把握しておくべきです。
アンダーレイとオーバーレイの分離が重要
Direct ConnectとVPNのように異なるネットワーク層では、IPアドレスの管理を明確に分離し、相互の影響を最小限に抑える必要があります。
AWSサポートは強力な味方
自力での調査にも限界があるため、AWSの内部情報を持つサポートチームと協力することで、問題解決のスピードを大幅に上げることができます。
AWS Direct ConnectとSite-to-Site VPNの組み合わせは非常に強力ですが、設定の細かいミスが思わぬトラブルを引き起こすこともあります。今回の経験が、同じような環境を構築している方々の参考になれば幸いです。
次回のブログ記事では、今回の経験を踏まえ、Direct Connect上のSite-to-Site VPNの正しい設定方法について詳しく解説します。オンプレミスルーターの設定からAWS側の設定まで、ベストプラクティスを交えながら具体的な手順を紹介する予定です。どうぞお楽しみに!