Haskellで競技プログラミングをするための環境構築
内山浩佑
デロイト トーマツ ウェブサービス株式会社(DWS)公式ブログ
夏の訪れを徐々に感じているmickeyです。
今回は、PythonでStable Diffusionを実装し画像生成を試みたいと思います。Stable Diffusionは、画像生成の分野で特に使用されている技術です。巷に溢れている様々な画像生成AIも、大部分では裏側にこの技術が使用されています。この技術を実装することを通じて、画像生成について改めて理解を深めていきたいと思います。
今回目的とする生成画像は、Fashion-MNISTの衣類の画像です。Stable DiffusionでFashion-MNISTの画像を生成している記事があまり見当たらなかったので、この機会に試してみることにしました。
Fashion-MNISTは衣類の画像データセットで、機械学習と画像認識の研究のベンチマークによく用いられます。10種類の異なるファッションアイテムが、それぞれ28x28ピクセルのグレースケール画像として提供されています。従来のMNISTデータセット(手書き数字)の代替として、より複雑な課題を提供するものとなっています。
画像の一例としてこのようなものがあります(28x28ピクセルなので、画像はやや荒めです)。

付けられているラベルの番号と衣類の種類としては以下のようになっています。
| Label | Description |
| 0 | T-shirt/top (Tシャツ・トップス) |
| 1 | Trouser (ズボン) |
| 2 | Pullover (プルオーバー) |
| 3 | Dress (ドレス) |
| 4 | Coat (コート) |
| 5 | Sandal (サンダル) |
| 6 | Shirt (シャツ) |
| 7 | Sneaker (スニーカー) |
| 8 | Bag (バッグ) |
| 9 | Ankle boot (アンクルブーツ) |
※より詳細は、以下のURLを確認してください。
それでは、早速使用するコードの中身に入っていきたいと思います。
今回使用するコードは以下のようになります。Pytorchを主に使用しています。
以下のコードは、Jupyter NotebookやGoogle Colabでの実行を想定しています(今回私は、Jupyter Notebookを用いて実行しました)。
まず、実行に必要なライブラリをインストールします。
import math
import torch
import torchvision
from torch import nn
from tqdm import tqdm
import matplotlib.pyplot as plt
from torch.optim import Adam
import torch.nn.functional as F
from torchvision import transforms
from torch.utils.data import DataLoaderimg_size、batch_size、num_timesteps、epochs、lr は、それぞれ画像サイズ、バッチサイズ、タイムステップ数、エポック数、学習率を指定しています。
device は、GPUが利用可能な場合はcudaを、それ以外の場合はcpuを使用するように指定します。
img_size = 28
batch_size = 128
num_timesteps = 1000
epochs = 30
lr = 1e-3
device = 'cuda' if torch.cuda.is_available() else 'cpu'show_images 関数は、指定された画像をグリッド形式で表示します。
def show_images(images, rows=2, cols=10):
fig = plt.figure(figsize=(cols, rows))
i = 0
for r in range(rows):
for c in range(cols):
fig.add_subplot(rows, cols, i + 1)
plt.imshow(images[i].cpu().numpy().squeeze(), cmap='gray')
plt.axis('off')
i += 1
plt.show()
_pos_encoding 関数は、特定のタイムステップに対する位置エンコーディングを計算し、pos_encoding 関数は、バッチ全体の位置エンコーディングを計算します。
def _pos_encoding(time_idx, output_dim, device='cpu'):
t, D = time_idx, output_dim
v = torch.zeros(D, device=device)
i = torch.arange(0, D, device=device)
div_term = torch.exp(i / D * math.log(10000))
v[0::2] = torch.sin(t / div_term[0::2])
v[1::2] = torch.cos(t / div_term[1::2])
return v
def pos_encoding(timesteps, output_dim, device='cpu'):
batch_size = len(timesteps)
device = timesteps.device
v = torch.zeros(batch_size, output_dim, device=device)
for i in range(batch_size):
v[i] = _pos_encoding(timesteps[i], output_dim, device)
return v
ConvBlock クラスにて、畳み込み層とMLPを組み合わせたブロックを定義します。
class ConvBlock(nn.Module):
def __init__(self, in_ch, out_ch, time_embed_dim):
super().__init__()
self.convs = nn.Sequential(
nn.Conv2d(in_ch, out_ch, 3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(),
nn.Conv2d(out_ch, out_ch, 3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU()
)
self.mlp = nn.Sequential(
nn.Linear(time_embed_dim, in_ch),
nn.ReLU(),
nn.Linear(in_ch, in_ch)
)
def forward(self, x, v):
N, C, _, _ = x.shape
v = self.mlp(v)
v = v.view(N, C, 1, 1)
y = self.convs(x + v)
return y
UNet クラスにて、U-Netアーキテクチャを実装しています。さきほど定義したConvBlock関数を使用し、エンコーダ、デコーダ、スキップコネクションを含み、タイムステップの位置エンコーディングも統合します。
class UNet(nn.Module):
def __init__(self, in_ch=1, time_embed_dim=100):
super().__init__()
self.time_embed_dim = time_embed_dim
self.down1 = ConvBlock(in_ch, 64, time_embed_dim)
self.down2 = ConvBlock(64, 128, time_embed_dim)
self.bot1 = ConvBlock(128, 256, time_embed_dim)
self.up2 = ConvBlock(128 + 256, 128, time_embed_dim)
self.up1 = ConvBlock(128 + 64, 64, time_embed_dim)
self.out = nn.Conv2d(64, in_ch, 1)
self.maxpool = nn.MaxPool2d(2)
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear')
def forward(self, x, timesteps):
v = pos_encoding(timesteps, self.time_embed_dim, x.device)
x1 = self.down1(x, v)
x = self.maxpool(x1)
x2 = self.down2(x, v)
x = self.maxpool(x2)
x = self.bot1(x, v)
x = self.upsample(x)
x = torch.cat([x, x2], dim=1)
x = self.up2(x, v)
x = self.upsample(x)
x = torch.cat([x, x1], dim=1)
x = self.up1(x, v)
x = self.out(x)
return xDiffuser クラスにて、diffusionプロセスを管理し、ノイズの追加および除去を行います。
add_noise関数にて、ノイズを画像に追加し、denoise関数にて、ノイズの除去を行います。
reverse_to_img関数にて、テンソルを画像に変換し、sample関数で、を用いて新しい画像を生成します。
class Diffuser:
def __init__(self, num_timesteps=1000, beta_start=0.0001, beta_end=0.02, device='cpu'):
self.num_timesteps = num_timesteps
self.device = device
self.betas = torch.linspace(beta_start, beta_end, num_timesteps, device=device)
self.alphas = 1 - self.betas
self.alpha_bars = torch.cumprod(self.alphas, dim=0)
def add_noise(self, x_0, t):
T = self.num_timesteps
assert (t >= 1).all() and (t <= T).all()
t_idx = t - 1 # alpha_bars[0] is for t=1
alpha_bar = self.alpha_bars[t_idx] # (N,)
N = alpha_bar.size(0)
alpha_bar = alpha_bar.view(N, 1, 1, 1) # (N, 1, 1, 1)
noise = torch.randn_like(x_0, device=self.device)
x_t = torch.sqrt(alpha_bar) * x_0 + torch.sqrt(1 - alpha_bar) * noise
return x_t, noise
def denoise(self, model, x, t):
T = self.num_timesteps
assert (t >= 1).all() and (t <= T).all()
t_idx = t - 1 # alphas[0] is for t=1
alpha = self.alphas[t_idx]
alpha_bar = self.alpha_bars[t_idx]
alpha_bar_prev = self.alpha_bars[t_idx-1]
N = alpha.size(0)
alpha = alpha.view(N, 1, 1, 1)
alpha_bar = alpha_bar.view(N, 1, 1, 1)
alpha_bar_prev = alpha_bar_prev.view(N, 1, 1, 1)
model.eval()
with torch.no_grad():
eps = model(x, t)
model.train()
noise = torch.randn_like(x, device=self.device)
noise[t == 1] = 0 # no noise at t=1
mu = (x - ((1-alpha) / torch.sqrt(1-alpha_bar)) * eps) / torch.sqrt(alpha)
std = torch.sqrt((1-alpha) * (1-alpha_bar_prev) / (1-alpha_bar))
return mu + noise * std
def reverse_to_img(self, x):
x = x * 255
x = x.clamp(0, 255)
x = x.to(torch.uint8)
x = x.cpu()
to_pil = transforms.ToPILImage()
return to_pil(x)
def sample(self, model, x_shape=(20, 1, 28, 28)):
batch_size = x_shape[0]
x = torch.randn(x_shape, device=self.device)
for i in tqdm(range(self.num_timesteps, 0, -1)):
t = torch.tensor([i] * batch_size, device=self.device, dtype=torch.long)
x = self.denoise(model, x, t)
images = [self.reverse_to_img(x[i]) for i in range(batch_size)]
return images
Fashion MNISTデータセットを取得し、前処理としてテンソルに変換します。
データローダを作成し、batch sizeとshuffleを設定します。
preprocess = transforms.ToTensor()
dataset = torchvision.datasets.FashionMNIST(root='./data', download=True, transform=preprocess)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)dataloaderからsample画像を取得し、表示します。
# Display some images from the dataset
data_iter = iter(dataloader)
images, labels = next(data_iter)
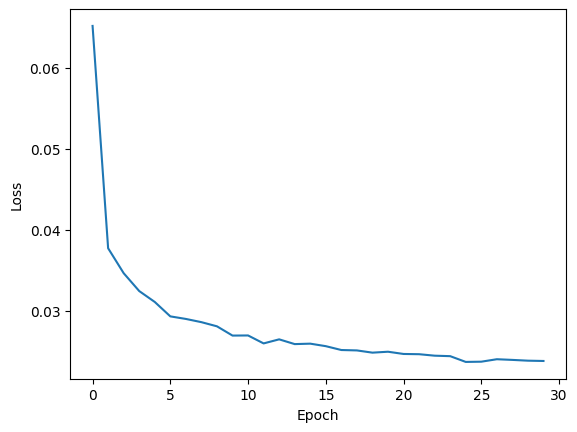
show_images(images[:20], rows=2, cols=10)エポック数を30に設定した結果、以下のように学習が進みました。
エポック数が増加するにつれて、Lossが緩やかに減少していることがわかります。
生成結果としては、以下のようになりました。
1回目の生成結果です。まだこの時点では、衣類の原型を留めていないような画像が生成されています。
5回目の生成結果です。ここで、Tシャツや靴といった形らしい画像が生成されるようになってきました!ただ、まだ全体的に白っぽい画像になっており、詳細な色やデザインといった箇所の生成はまだできていない印象を受けます。

そして、こちらが30回目の生成結果です。ここまでくると、具体的なデザインや色調を含めて、Fashion-MNISTにある画像っぽいものが生成されています!

今回は、昨今の画像生成AIなどで多用させている技術であるStable Diffusionを実際にPythonで実装し、Fashion-MNISTの画像を生成してみました。巷に溢れている画像生成AIの裏側でこのような実装がされているのだなぁ、と少しでも思っていただければ望外の喜びと存じます。
ここまで読んでいただいたみなさん、ありがとうございました。





